Data structure
In computer science, a data structure is a data organization, management, and storage format that enables efficient access and modification. More precisely, a data structure is a collection of data values, the relationships among them, and the functions or operations that can be applied to the data, it is an algebraic structure about data.
Stack Queue Array Linked List Tree Graph Heap Hash table
Tree
In computer science, a tree is a widely used abstract data type that simulates a hierarchical tree structure, with a root value and subtrees of children with a parent node, represented as a set of linked nodes.
A tree data structure can be defined recursively as a collection of nodes, where each node is a data structure consisting of a value and a list of references to nodes. The start of the tree is the “root node” and the reference nodes are the “children”. No reference is duplicated and none points to the root.
Alternatively, a tree can be defined abstractly as a whole (globally) as an ordered tree, with a value assigned to each node. Both these perspectives are useful: while a tree can be analyzed mathematically as a whole, when actually represented as a data structure it is usually represented and worked with separately by node (rather than as a set of nodes and an adjacency list of edges between nodes, as one may represent a digraph, for instance). For example, looking at a tree as a whole, one can talk about “the parent node” of a given node, but in general, as a data structure, a given node only contains the list of its children but does not contain a reference to its parent (if any).
在计算机科学中,树(英语:tree)是一种抽象数据类型(ADT)或是实现这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。它是由n(n>0)个有限节点组成一个具有层次关系的集合合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
- 每个节点都只有有限个子节点或无子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树;
- 树里面没有环路(cycle)
术语
- 节点的度:一个节点含有的子树的个数称为该节点的度;
- 树的度:一棵树中,最大的节点度称为树的度;
- 叶节点或终端节点:度为零的节点;
- 非终端节点或分支节点:度不为零的节点;
- 父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 深度:对于任意节点n,n的深度为从根到n的唯一路径长,根的深度为0;
- 高度:对于任意节点n,n的高度为从n到一片树叶的最长路径长,所有树叶的高度为0;
- 堂兄弟节点:父节点在同一层的节点互为堂兄弟;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
- 森林:由m(m>=0)棵互不相交的树的集合称为森林;
树的种类
无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树。
有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树;
二叉树
:每个节点最多含有两个子树的树称为二叉树;
完全二叉树
:对于一棵二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树;
- 满二叉树:所有叶节点都在最底层的完全二叉树;
平衡二叉树:当且仅当任何节点的两棵子树的高度差不大于1的二叉树;
排序二叉树(二叉查找树(英语:Binary Search Tree)):也称二叉搜索树、有序二叉树、二分搜索树;
平衡二叉搜索树(英语:Balanced Binary Search Tree)是一种结构平衡的二叉搜索树,它是一种每个节点的左右两子树高度差都不超过一的二叉树。它能在O(内完成插入、查找和删除操作,最早被发明的平衡二叉搜索树为AVL树。
常见的平衡二叉搜索树有:
AVL树
红黑树
霍夫曼树:带权路径最短的二叉树称为哈夫曼树或最优二叉树;
B树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多于两个子树。
二分搜索树的前中后序遍历
关键 递归 递归顺序都是一样的,递归中一个根节点有三次接触机会,根节点的输出的时机不同
遍历方式的命名 如果把左节点和右节点的位置固定不动,那么根节点放在左节点的左边,称为前序(pre-order)、根节点放在左节点和右节点的中间,称为中序(in-order)、根节点放在右节点的右边,称为后序(post-order)。
前序遍历 Pre-Order Traversal(先根遍历 先序遍历)
根结点 —> 左子树 —> 右子树
先访问当前节点,再依次递归访问左右子树
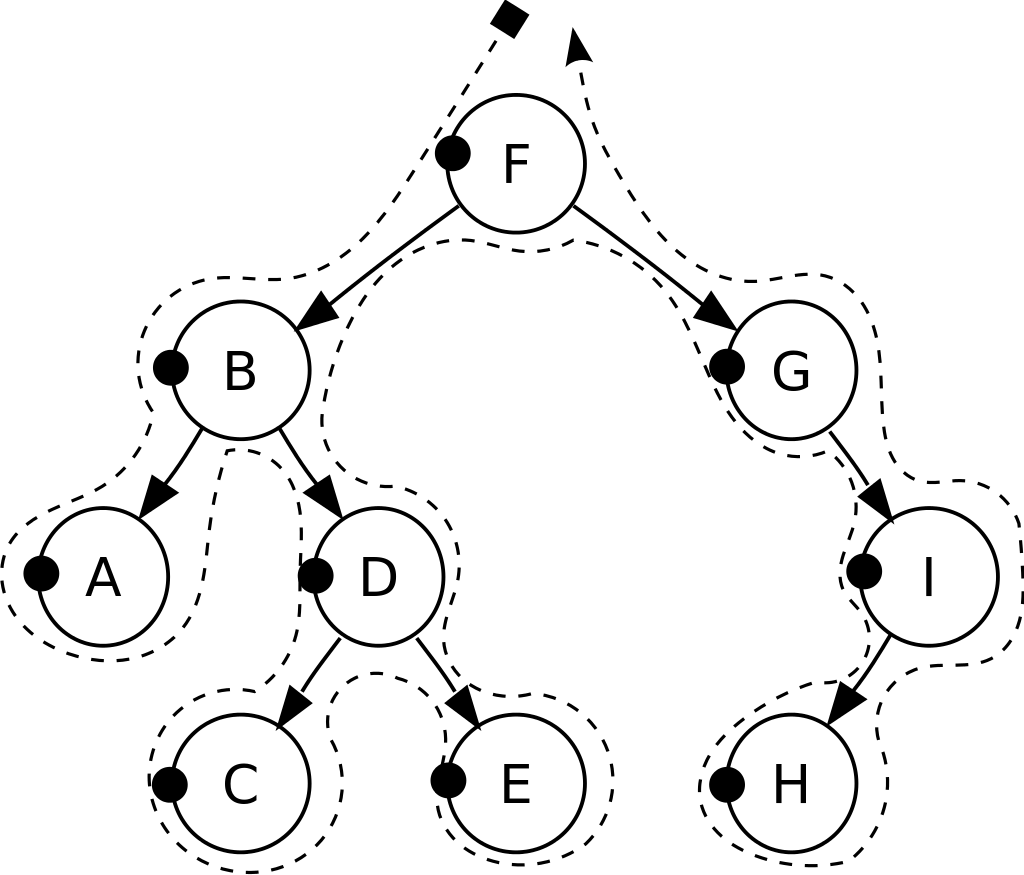
前序遍历:F, B, A, D, C, E, G, I, H.
中序遍历 In-Order Traversal
左子树—> 根结点 —> 右子树
先递归访问左子树,再访问自身,再递归访问右子树
结果按从小到大输出
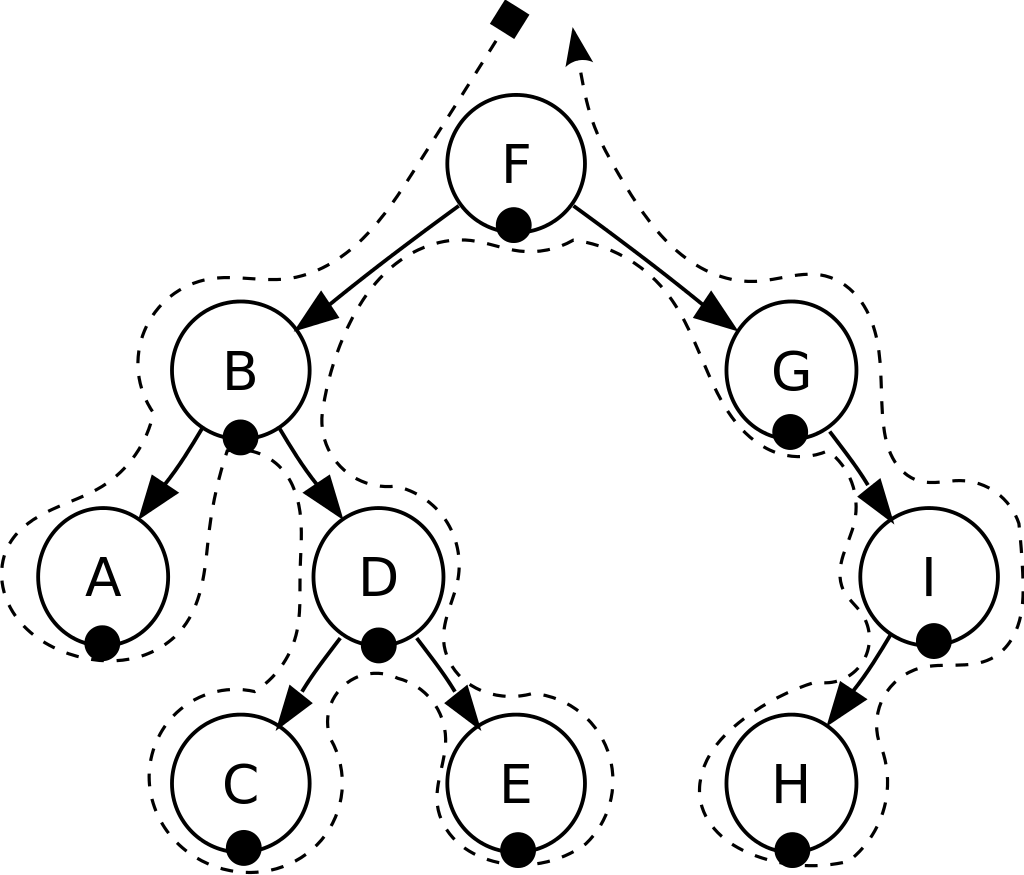
中序遍历:A, B, C, D, E, F, G, H, I.
后序遍历 Post-Order Traversal
左子树 —> 右子树 —> 根结点
先递归访问左右子树,再访问自身节点
左右子树都输出完在输出自身节点
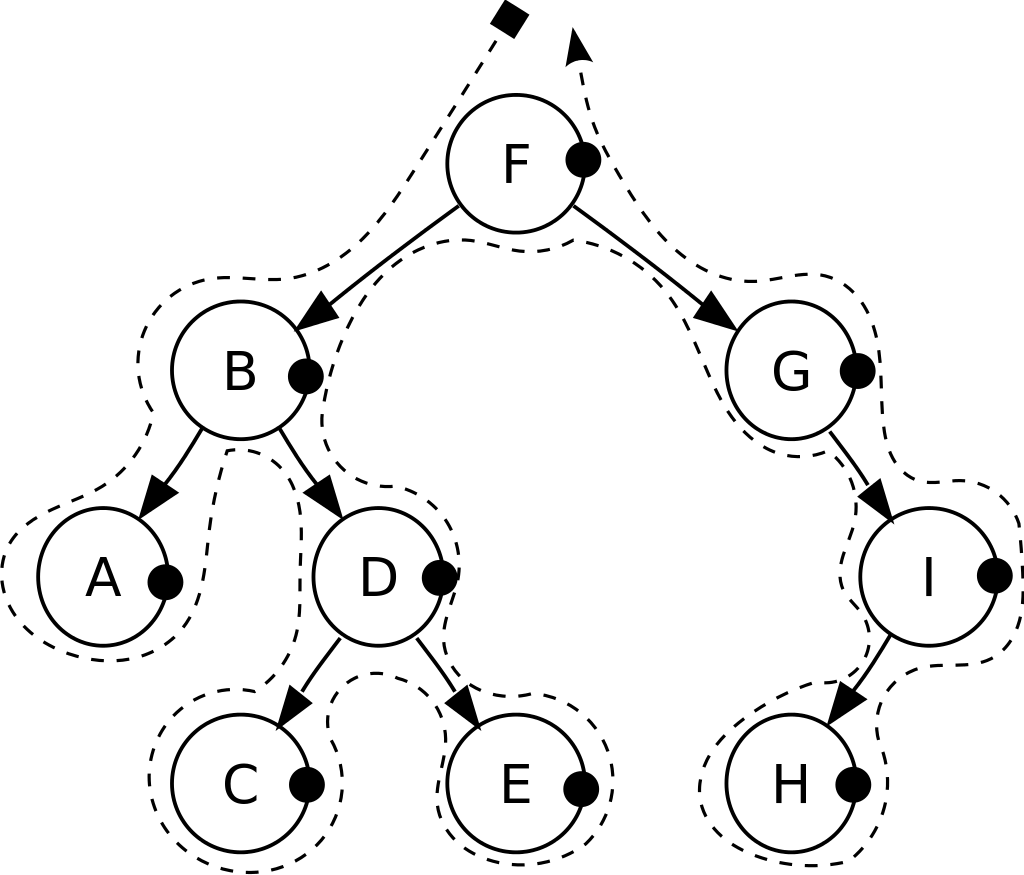
后序遍历:A, C, E, D, B, H, I, G, F.
#include <iostream>
#include <queue>
#include <ctime>
using namespace std;
// 二分搜索树
template <typename Key, typename Value>
class BST{
private:
// 树中的节点为私有的结构体, 外界不需要了解二分搜索树节点的具体实现
struct Node{
Key key;
Value value;
Node *left;
Node *right;
Node(Key key, Value value){
this->key = key;
this->value = value;
this->left = this->right = NULL;
}
};
Node *root; // 根节点
int count; // 树中的节点个数
public:
// 构造函数, 默认构造一棵空二分搜索树
BST(){
root = NULL;
count = 0;
}
// 析构函数, 释放二分搜索树的所有空间
~BST(){
destroy( root );
}
// 返回二分搜索树的节点个数
int size(){
return count;
}
// 返回二分搜索树是否为空
bool isEmpty(){
return count == 0;
}
// 向二分搜索树中插入一个新的(key, value)数据对
void insert(Key key, Value value){
root = insert(root, key, value);
}
// 查看二分搜索树中是否存在键key
bool contain(Key key){
return contain(root, key);
}
// 在二分搜索树中搜索键key所对应的值。如果这个值不存在, 则返回NULL
Value* search(Key key){
return search( root , key );
}
// 二分搜索树的前序遍历
void preOrder(){
preOrder(root);
}
// 二分搜索树的中序遍历
void inOrder(){
inOrder(root);
}
// 二分搜索树的后序遍历
void postOrder(){
postOrder(root);
}
private:
// 向以node为根的二分搜索树中, 插入节点(key, value), 使用递归算法
// 返回插入新节点后的二分搜索树的根
Node* insert(Node *node, Key key, Value value){
if( node == NULL ){
count ++;
return new Node(key, value);
}
if( key == node->key )
node->value = value;
else if( key < node->key )
node->left = insert( node->left , key, value);
else // key > node->key
node->right = insert( node->right, key, value);
return node;
}
// 查看以node为根的二分搜索树中是否包含键值为key的节点, 使用递归算法
bool contain(Node* node, Key key){
if( node == NULL )
return false;
if( key == node->key )
return true;
else if( key < node->key )
return contain( node->left , key );
else // key > node->key
return contain( node->right , key );
}
// 在以node为根的二分搜索树中查找key所对应的value, 递归算法
// 若value不存在, 则返回NULL
Value* search(Node* node, Key key){
if( node == NULL )
return NULL;
if( key == node->key )
return &(node->value);
else if( key < node->key )
return search( node->left , key );
else // key > node->key
return search( node->right, key );
}
// 对以node为根的二叉搜索树进行前序遍历, 递归算法
void preOrder(Node* node){
if( node != NULL ){
cout<<node->key<<endl;
preOrder(node->left);
preOrder(node->right);
}
}
// 对以node为根的二叉搜索树进行中序遍历, 递归算法
void inOrder(Node* node){
if( node != NULL ){
inOrder(node->left);
cout<<node->key<<endl;
inOrder(node->right);
}
}
// 对以node为根的二叉搜索树进行后序遍历, 递归算法
void postOrder(Node* node){
if( node != NULL ){
postOrder(node->left);
postOrder(node->right);
cout<<node->key<<endl;
}
}
// 释放以node为根的二分搜索树的所有节点
// 采用后续遍历的递归算法
void destroy(Node* node){
if( node != NULL ){
destroy( node->left );
destroy( node->right );
delete node;
count --;
}
}
};
// 测试二分搜索树的前中后序遍历
int main() {
srand(time(NULL));
BST<int,int> bst = BST<int,int>();
// 取n个取值范围在[0...m)的随机整数放进二分搜索树中
int N = 10;
int M = 100;
for( int i = 0 ; i < N ; i ++ ){
int key = rand()%M;
// 为了后续测试方便,这里value值取和key值一样
int value = key;
cout<<key<<" ";
bst.insert(key,value);
}
cout<<endl;
// 测试二分搜索树的size()
cout<<"size: "<<bst.size()<<endl<<endl;
// 测试二分搜索树的前序遍历 preOrder
cout<<"preOrder: "<<endl;
bst.preOrder();
cout<<endl;
// 测试二分搜索树的中序遍历 inOrder
cout<<"inOrder: "<<endl;
bst.inOrder();
cout<<endl;
// 测试二分搜索树的后序遍历 postOrder
cout<<"postOrder: "<<endl;
bst.postOrder();
cout<<endl;
return 0;
}AVL树 (对二分搜索树的改进)
维基百科
AVL树(Adelson-Velsky and Landis Tree)是计算机科学中最早被发明的自平衡二叉查找树。在AVL树中,任一节点对应的两棵子树的最大高度差为1,因此它也被称为高度平衡树。查找、插入和删除在平均和最坏情况下的时间复杂度都是(logn)。增加和删除元素的操作则可能需要借由一次或多次树旋转,以实现树的重新平衡。AVL树得名于它的发明者G. M. Adelson-Velsky和Evgenii Landis,他们在1962年的论文《An algorithm for the organization of information》中公开了这一数据结构。
节点的平衡因子是它的左子树的高度减去它的右子树的高度(有时相反)。带有平衡因子1、0或 -1的节点被认为是平衡的。带有平衡因子 -2或2的节点被认为是不平衡的,并需要重新平衡这个树。平衡因子可以直接存储在每个节点中,或从可能存储在节点中的子树高度计算出来。
百度百科
在计算机科学中,AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个子树的高度最大差别为1,所以它也被称为高度平衡树。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。AVL树得名于它的发明者G. M. Adelson-Velsky和E. M. Landis,他们在1962年的论文《An algorithm for the organization of information》中发表了它。
AVL树本质上还是一棵二叉搜索树,它的特点是:
1.本身首先是一棵二叉搜索树。
2.带有平衡条件:每个结点的左右子树的高度之差的绝对值(平衡因子)最多为1。
也就是说,AVL树,本质上是带了平衡功能的二叉查找树(二叉排序树,二叉搜索树)。
总的来说,AVL树是对二叉搜索树的一种改进,是一种自平衡的二叉搜索树。在二叉树搜索树插入的时候,如果不平衡会自动进行调整,使二叉搜索树平衡(每个结点的左右子树的高度之差的绝对值最多为1)
操作
AVL树的基本操作一般涉及运作同在不平衡的二叉查找树所运作的同样的算法。但是要进行预先或随后做一次或多次所谓的”AVL旋转”。
以下图表以四列表示四种情况,每行表示在该种情况下要进行的操作。在左左和右右的情况下,只需要进行一次旋转操作;在左右和右左的情况下,需要进行两次旋转操作。
红黑树
红黑树是每个节点都带有颜色属性的[二叉查找树],颜色为红色或黑色。在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
- 节点是红色或黑色。
- 根是黑色。
- 所有叶子都是黑色(叶子是NIL节点)。
- 每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
- 从任一节点到其每个叶子的所有[简单路径]都包含相同数目的黑色节点。
R-B Tree,全称是Red-Black Tree,又称为“红黑树”,它一种特殊的二叉查找树。红黑树的每个节点上都有存储位表示节点的颜色,可以是红(Red)或黑(Black)。
口诀:左根右,根叶黑,不红红,黑路同。
红黑树的特性:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
注意:
(01) 特性(3)中的叶子节点,是只为空(NIL或null)的节点。
(02) 特性(5),确保没有一条路径会比其他路径长出俩倍。因而,红黑树是相对是接近平衡的二叉树。
红黑树示意图如下:
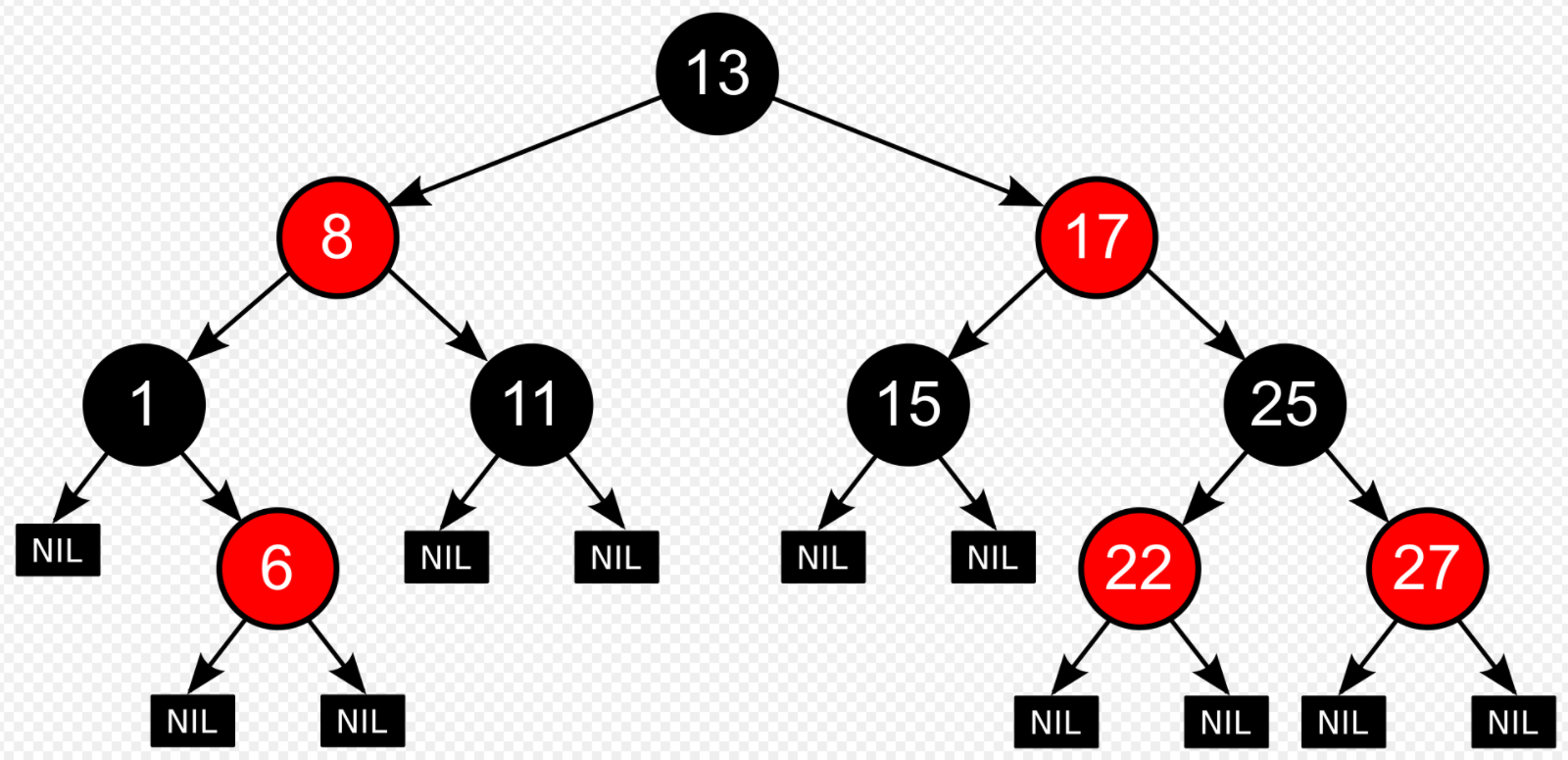
哈希表
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
若关键字为k,则其值存放在f(k)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数,按这个思想建立的表为散列表。
对不同的关键字可能得到同一散列地址,即k1≠k2,而f(k1)==f(k2),这种现象称为冲突(英语:Collision)。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数f(k)和处理冲突的方法将一组关键字映射到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便称为散列表,这一映射过程称为散列造表或散列,所得的存储位置称散列地址。
若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数(Uniform Hash function),这就是使关键字经过散列函数得到一个“随机的地址”,从而减少冲突。
散列表(hash table)又称为哈希表。是一种数据结构,特点是:数据元素的关键字与其存储地址直接相关
如何建立 关键字与存储地址的联系
通过 散列函数 哈希函数 addr = H(key)
散列函数 H(key) = key%13
处理冲突的方法
拉链法 链接法 链地址法 把所有 同义词存储在一个链表中
并查集 Union Find
连接问题
网络中节点间的连接状态
网络是个抽象的概念:用户之间形成的网络
数学中的集合类实现
并查集 的并就是数学集合中的并
连接问题和路径问题
比路径问题要回答的问题少
1.和二分查找作比较
2.和select作比较
3.和堆作比较
并查集
对于一组数据,主要支持两个动作
union(p,q)
find(p)
用来回答一个问题 isConnected(p,q) 连接问题
并查集的一种实现思路Quick Find
并查集的基本数据表示 数组
| Id(数组下标) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| Id[i] | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
比如,0到4对应的值为0,它们之间是相互连接的。5到9对应的值为1,它们是相互连接的。
// 查找过程, 查找元素p所对应的集合编号
int find(int p) {
assert(p >= 0 && p <= count);
return id[p];
}
// 查看元素p和元素q是否所属一个集合
// O(1)复杂度
bool isConnected(int p, int q) {
return find(p) == find(q);
}// 合并元素p和元素q所属的集合
// O(n) 复杂度
void unionSet(int p, int q) {
int pId = find(p);
int qId = find(q);
if (pId == qId)
return;
// 合并过程需要遍历一遍所有元素, 将两个元素的所属集合编号合并,就是合并两个集合
for (int i = 0; i < count; i++) {
if (id[i] == pId)
id[i] = qId;
}
}并查集的另外一种实现思路Quick Union
将每一个元素,看做是一个节点
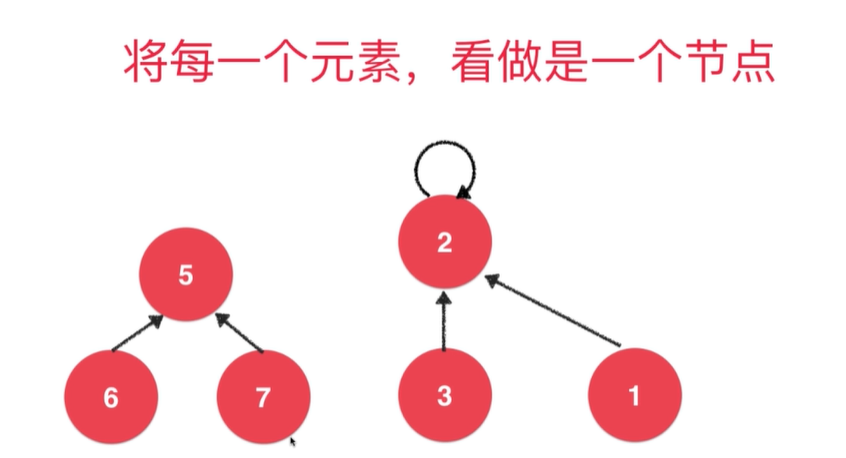
连接的时候,使用一个根指向另有一个根
int find(int p) {
assert(p >= 0 && p <= count);
while (p != parent[p])
p = parent[p];
return p;
}bool isConnected(int p, int q) {
return find(p) == find(q);
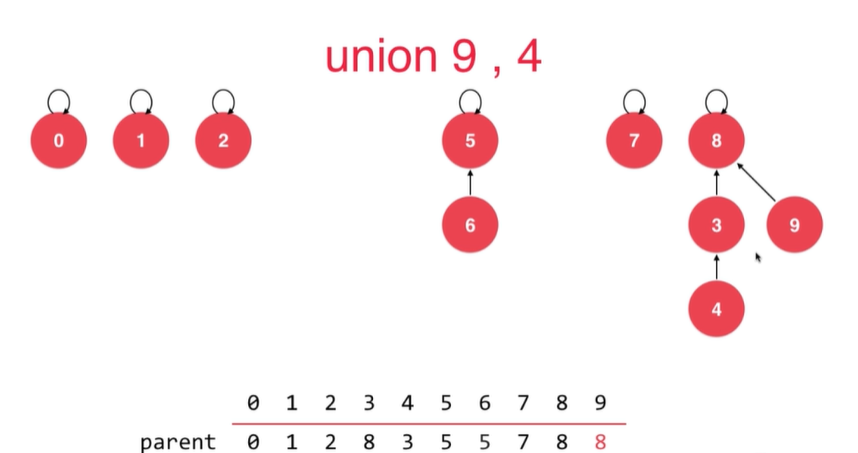
}void unionSet(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
parent[pRoot] = qRoot;
}完整实现
//
// Created by mo on 2021/7/29.
//
#ifndef UNIONFIND_UNIONFIND_H
#define UNIONFIND_UNIONFIND_H
#include <iostream>
#include <cassert>
using namespace std;
//第一版Union-Find
namespace UF1 {
class UnionFind {
private:
int *id;//Union-Find本质就是一个数组
int count; // 数据个数
public:
// 构造函数
UnionFind(int n) {
count = n;
id = new int[n];
// 初始化, 每一个id[i]指向自己, 没有合并的元素
for (int i = 0; i < n; i++)
id[i] = i;
}
//析构函数
~UnionFind() {
delete[] id;
}
// 查找过程, 查找元素p所对应的集合编号
int find(int p) {
assert(p >= 0 && p <= count);
return id[p];
}
// 查看元素p和元素q是否所属一个集合
// O(1)复杂度
bool isConnected(int p, int q) {
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(n) 复杂度
void unionSet(int p, int q) {
int pId = find(p);
int qId = find(q);
if (pId == qId)
return;
// 合并过程需要遍历一遍所有元素, 将两个元素的所属集合编号合并,就是合并两个集合
for (int i = 0; i < count; i++) {
if (id[i] == pId)
id[i] = qId;
}
}
};
}
//第二版Union-Find
namespace UF2 {
class UnionFind {
private:
int *parent;
int count;
public:
UnionFind(int count) {
parent = new int[count];
this->count = count;
for (int i = 0; i < count; i++) {
parent[i] = i;
}
}
~UnionFind() {
delete[] parent;
}
int find(int p) {
assert(p >= 0 && p <= count);
while (p != parent[p])
p = parent[p];
return p;
}
bool isConnected(int p, int q) {
return find(p) == find(q);
}
void unionSet(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
parent[pRoot] = qRoot;
}
};
}
//第三版Union-Find
namespace UF3 {
class UnionFind {
private:
int *parent; // parent[i]表示第i个元素所指向的父节点
int *sz;// sz[i]表示以i为根的集合中元素个数
int count;// 数据个数
public:
//构造函数
UnionFind(int count) {
parent = new int[count];
sz = new int[count];
this->count = count;
for (int i = 0; i < count; i++) {
parent[i] = i;
sz[i] = 1;
}
}
//析构函数
~UnionFind() {
delete[] parent;
delete[] sz;
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
int find(int p) {
assert(p >= 0 && p <= count);
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while (p != parent[p]) {
p = parent[p];
}
return p;
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
bool isConnected(int p, int q) {
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
void unionSet(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
// 根据两个元素所在树的元素个数不同判断合并方向
// 将元素个数少的集合合并到元素个数多的集合上
if (sz[pRoot] < sz[qRoot]) {
parent[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
} else {
parent[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
}
};
}
//第四版Union-Find
namespace UF4 {
class UnionFind {
private:
int *rank; // rank[i]表示以i为根的集合所表示的树的层数
int *parent;// parent[i]表示第i个元素所指向的父节点
int count; // 数据个数
public:
//构造函数
UnionFind(int count) {
parent = new int[count];
rank = new int[count];
this->count = count;
for (int i = 0; i < count; i++) {
parent[i] = i;
rank[i] = 1;
}
}
~UnionFind() {
delete[] parent;
delete[] rank;
}
int find(int p) {
assert(p >= 0 && p <= count);
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while (p != parent[p]) {
p = parent[p];
}
return p;
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
bool isConnected(int p, int q) {
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
void unionSet(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
// 根据两个元素所在树的元素个数不同判断合并方向
// 将元素个数少的集合合并到元素个数多的集合上
if (rank[pRoot] < rank[qRoot]) {
parent[pRoot] = qRoot;
} else if (rank[pRoot] > rank[qRoot]) {
parent[qRoot] = pRoot;
} else {// rank[pRoot] == rank[qRoot]
parent[pRoot] = qRoot;
rank[qRoot] += 1; // 此时, 我维护rank的值
}
}
};
}
namespace UF5 {
// rank[i]表示以i为根的集合所表示的树的层数
// 在后续的代码中, 我们并不会维护rank的语意, 也就是rank的值在路径压缩的过程中, 有可能不在是树的层数值
// 这也是我们的rank不叫height或者depth的原因, 他只是作为比较的一个标准
class UnionFind {
public: // 后续, 我们要在外部操控并查集的数据, 在这里使用public
int *parent; // parent[i]表示第i个元素所指向的父节点
private:
int *rank; // rank[i]表示以i为根的集合所表示的树的层数
// int* parent;// parent[i]表示第i个元素所指向的父节点
int count; // 数据个数
public:
//构造函数
UnionFind(int count) {
parent = new int[count];
rank = new int[count];
this->count = count;
for (int i = 0; i < count; i++) {
parent[i] = i;
rank[i] = 1;
}
}
~UnionFind() {
delete[] parent;
delete[] rank;
}
int find(int p) {
assert(p >= 0 && p < count);
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
// path compression 1
while (p != parent[p]) {
parent[p] = parent[parent[p]];
p = parent[p];
}
return p;
// path compression 2, 递归算法
// if (p != parent[p]){
// parent[p] = find(parent[p]);
// }
// return parent[p];
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
bool isConnected(int p, int q) {
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
void unionSet(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
// 根据两个元素所在树的元素个数不同判断合并方向
// 将元素个数少的集合合并到元素个数多的集合上
if (rank[pRoot] < rank[qRoot]) {
parent[pRoot] = qRoot;
} else if (rank[pRoot] > rank[qRoot]) {
parent[qRoot] = pRoot;
} else {// rank[pRoot] == rank[qRoot]
parent[pRoot] = qRoot;
rank[qRoot] += 1; // 此时, 我维护rank的值
}
}
// 打印输出并查集中的parent数据
void show() {
for (int i = 0; i < count; i++)
cout << parent[i] << " ";
cout << endl;
}
};
}
namespace UF6 {
// rank[i]表示以i为根的集合所表示的树的层数
// 在后续的代码中, 我们并不会维护rank的语意, 也就是rank的值在路径压缩的过程中, 有可能不在是树的层数值
// 这也是我们的rank不叫height或者depth的原因, 他只是作为比较的一个标准
class UnionFind {
public: // 后续, 我们要在外部操控并查集的数据, 在这里使用public
int *parent; // parent[i]表示第i个元素所指向的父节点
private:
int *rank; // rank[i]表示以i为根的集合所表示的树的层数
// int* parent;// parent[i]表示第i个元素所指向的父节点
int count; // 数据个数
public:
//构造函数
UnionFind(int count) {
parent = new int[count];
rank = new int[count];
this->count = count;
for (int i = 0; i < count; i++) {
parent[i] = i;
rank[i] = 1;
}
}
~UnionFind() {
delete[] parent;
delete[] rank;
}
int find(int p) {
assert(p >= 0 && p < count);
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
// path compression 1
// while(p != parent[p]){
// parent[p] = parent[parent[p]];
// p = parent[p];
// }
// return p;
// path compression 2, 递归算法
if (p != parent[p]) {
parent[p] = find(parent[p]);
}
return parent[p];
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
bool isConnected(int p, int q) {
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
void unionSet(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
// 根据两个元素所在树的元素个数不同判断合并方向
// 将元素个数少的集合合并到元素个数多的集合上
if (rank[pRoot] < rank[qRoot]) {
parent[pRoot] = qRoot;
} else if (rank[pRoot] > rank[qRoot]) {
parent[qRoot] = pRoot;
} else {// rank[pRoot] == rank[qRoot]
parent[pRoot] = qRoot;
rank[qRoot] += 1; // 此时, 我维护rank的值
}
}
// 打印输出并查集中的parent数据
void show() {
for (int i = 0; i < count; i++)
cout << parent[i] << " ";
cout << endl;
}
};
}
#endif //UNIONFIND_UNIONFIND_H
//
// Created by mozhenhai on 2021/7/30.
//
#ifndef UNIONFIND_UNIONFINDTESTHELPER_H
#define UNIONFIND_UNIONFINDTESTHELPER_H
#include <iostream>
#include <ctime>
#include <vector>
#include "UnionFind.h"
using namespace std;
// 测试并查集的辅助函数
namespace UnionFindTestHelper {
// 测试第一版本的并查集, 测试元素个数为n
void testUF1(int n) {
srand(time(NULL));
UF1::UnionFind uf = UF1::UnionFind(n);
time_t startTime = clock();
// 进行n次操作, 每次随机选择两个元素进行合并操作
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
uf.unionSet(a, b);
}
// 再进行n次操作, 每次随机选择两个元素, 查询他们是否同属一个集合
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
uf.isConnected(a, b);
}
time_t endTime = clock();
// 打印输出对这2n个操作的耗时
cout << "UF1, " << 2 * n << " ops, " << double(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl;
}
// 测试第二版本的并查集, 测试元素个数为n
void testUF2(int n) {
srand(time(NULL));
UF2::UnionFind uf = UF2::UnionFind(n);
time_t startTime = clock();
// 进行n次操作, 每次随机选择两个元素进行合并操作
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
uf.unionSet(a, b);
}
// 再进行n次操作, 每次随机选择两个元素, 查询他们是否同属一个集合
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
uf.isConnected(a, b);
}
time_t endTime = clock();
// 打印输出对这2n个操作的耗时
cout << "UF2, " << 2 * n << " ops, " << double(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl;
}
// 测试第三版本的并查集, 测试元素个数为n
void testUF3(int n) {
srand(time(NULL));
UF3::UnionFind uf = UF3::UnionFind(n);
time_t startTime = clock();
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
uf.unionSet(a, b);
}
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
uf.isConnected(a, b);
}
time_t endTime = clock();
cout << "UF3, " << 2 * n << " ops, " << double(endTime - startTime) / CLOCKS_PER_SEC << " s" << endl;
}
// 测试第四版本的并查集, 测试元素个数为n
void testUF4(int n) {
srand(time(NULL));
UF4::UnionFind uf = UF4::UnionFind(n);
time_t startTime = clock();
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
uf.unionSet(a, b);
}
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
uf.isConnected(a, b);
}
time_t endTime = clock();
cout << "UF4, " << 2 * n << " ops, " << double(endTime - startTime) / CLOCKS_PER_SEC << " s" << endl;
}
// 测试第五版本的并查集, 测试元素个数为n
void testUF5(int n) {
srand(time(NULL));
UF5::UnionFind uf = UF5::UnionFind(n);
time_t startTime = clock();
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
uf.unionSet(a, b);
}
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
uf.isConnected(a, b);
}
time_t endTime = clock();
cout << "UF5, " << 2 * n << " ops, " << double(endTime - startTime) / CLOCKS_PER_SEC << " s" << endl;
}
// 测试第六版本的并查集, 测试元素个数为n
void testUF6(int n) {
srand(time(NULL));
UF6::UnionFind uf = UF6::UnionFind(n);
time_t startTime = clock();
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
uf.unionSet(a, b);
}
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
uf.isConnected(a, b);
}
time_t endTime = clock();
cout << "UF6, " << 2 * n << " ops, " << double(endTime - startTime) / CLOCKS_PER_SEC << " s" << endl;
}
// 使用相同的测试数据测试UF的执行效率
template<typename UF>
void testUF(const string &ufName, UF &uf, const vector<pair<int, int>> &unionTest,
const vector<pair<int, int>> &connectTest) {
time_t startTime = clock();
for (int i = 0; i < unionTest.size(); i++) {
int a = unionTest[i].first;
int b = unionTest[i].second;
uf.unionSet(a, b);
}
for (int i = 0; i < connectTest.size(); i++) {
int a = connectTest[i].first;
int b = connectTest[i].second;
uf.isConnected(a, b);
}
time_t endTime = clock();
cout << ufName << " with " << unionTest.size() << " unionElements ops, ";
cout << connectTest.size() << " isConnected ops, ";
cout << double(endTime - startTime) / CLOCKS_PER_SEC << " s" << endl;
}
}
#endif //UNIONFIND_UNIONFINDTESTHELPER_H
//
// Created by mozhenhai on 2021/7/30.
//
#ifndef UNIONFIND_TEST_H
#define UNIONFIND_TEST_H
#include <iostream>
#include <cassert>
#include "UnionFindTestHelper.h"
// 使用相同的测试数据测试UF的执行效率
template<typename UF>
void testUF(const string &ufName, UF &uf, const vector<pair<int, int>> &unionTest,
const vector<pair<int, int>> &connectTest) {
time_t startTime = clock();
for (int i = 0; i < unionTest.size(); i++) {
int a = unionTest[i].first;
int b = unionTest[i].second;
uf.unionSet(a, b);
}
for (int i = 0; i < connectTest.size(); i++) {
int a = connectTest[i].first;
int b = connectTest[i].second;
uf.isConnected(a, b);
}
time_t endTime = clock();
cout << ufName << " with " << unionTest.size() << " unionElements ops, ";
cout << connectTest.size() << " isConnected ops, ";
cout << double(endTime - startTime) / CLOCKS_PER_SEC << " s" << endl;
}
void testUF123456() {
// 对比UF1, UF2, UF3, UF4, UF5和UF6的时间性能
// 在这里, 我们对于不同的UnionFind的实现, 使用相同的测试用例, 让测试结果更加准确
// 使用5,000,000的数据规模
int n = 5000000;
srand(time(NULL));
// 生成unionElements的测试用例
vector<pair<int, int>> unionTest;
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
unionTest.push_back(make_pair(a, b));
}
// 生成isConnected的测试用例
vector<pair<int, int>> connectTest;
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
connectTest.push_back(make_pair(a, b));
}
// 测试我们的UF1 ~ UF6
// 100万数据对于UF1和UF2来说太慢了, 不再测试
// UF1::UnionFind uf1 = UF1::UnionFind(n);
// UnionFindTestHelper::testUF("UF1", uf1, unionTest, connectTest);
//
// UF2::UnionFind uf2 = UF2::UnionFind(n);
// UnionFindTestHelper::testUF("UF2", uf2, unionTest, connectTest);
UF3::UnionFind uf3 = UF3::UnionFind(n);
testUF("UF3", uf3, unionTest, connectTest);
UF4::UnionFind uf4 = UF4::UnionFind(n);
testUF("UF4", uf4, unionTest, connectTest);
UF5::UnionFind uf5 = UF5::UnionFind(n);
testUF("UF5", uf5, unionTest, connectTest);
UF6::UnionFind uf6 = UF6::UnionFind(n);
testUF("UF6", uf6, unionTest, connectTest);
}
void test() {
// 使用5,000,000的数据规模
int n = 5000000;
srand(time(NULL));
// 生成unionElements的测试用例
vector<pair<int, int>> unionTest;
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
unionTest.push_back(make_pair(a, b));
}
// 生成isConnected的测试用例
vector<pair<int, int>> connectTest;
for (int i = 0; i < n; i++) {
int a = rand() % n;
int b = rand() % n;
connectTest.push_back(make_pair(a, b));
}
// 测试我们的UF1 ~ UF6
// 100万数据对于UF1和UF2来说太慢了, 不再测试
// UF1::UnionFind uf1 = UF1::UnionFind(n);
// UnionFindTestHelper::testUF("UF1", uf1, unionTest, connectTest);
//
// UF2::UnionFind uf2 = UF2::UnionFind(n);
// UnionFindTestHelper::testUF("UF2", uf2, unionTest, connectTest);
UF3::UnionFind uf3 = UF3::UnionFind(n);
UnionFindTestHelper::testUF("UF3", uf3, unionTest, connectTest);
UF4::UnionFind uf4 = UF4::UnionFind(n);
UnionFindTestHelper::testUF("UF4", uf4, unionTest, connectTest);
UF5::UnionFind uf5 = UF5::UnionFind(n);
UnionFindTestHelper::testUF("UF5", uf5, unionTest, connectTest);
UF6::UnionFind uf6 = UF6::UnionFind(n);
UnionFindTestHelper::testUF("UF6", uf6, unionTest, connectTest);
}
void testUF56() {
// 为了能够方便地看出两种路径压缩算法的不同,我们只使用有5个元素的并查集进行试验
int n = 5;
UF5::UnionFind uf5 = UF5::UnionFind(n);
UF6::UnionFind uf6 = UF6::UnionFind(n);
// 我们将我们的并查集初始设置成如下的样子
// 0
// /
// 1
// /
// 2
// /
// 3
// /
// 4
for (int i = 1; i < n; i++) {
uf5.parent[i] = i - 1;
uf6.parent[i] = i - 1;
}
// 现在, 我们对两个并查集调用find(4)操作
uf5.find(n - 1);
uf6.find(n - 1);
// 通过show, 我们可以看出, 使用迭代的路径压缩, 我们的并查集变成这个样子:
// 0
// / \
// 1 2
// / \
// 3 4
cout << "UF implements Path Compression by recursion:" << endl;
uf5.show();
cout << endl;
// 使用递归的路径压缩, 我们的并查集变成这个样子:
// 0
// / / \ \
// 1 2 3 4
cout << "UF implements Path Compression without recursion:" << endl;
uf6.show();
// 大家也可以调大n的值, 看看结果的不同:)
}
#endif //UNIONFIND_TEST_H
#include <iostream>
#include "UnionFindTestHelper.h"
#include "test.h"
int main() {
std::cout << "Hello, World!" << std::endl;
// int n = 100000;
// UnionFindTestHelper::testUF1(n);
// UnionFindTestHelper::testUF2(n);
// UnionFindTestHelper::testUF3(n);
// UnionFindTestHelper::testUF4(n);
// UnionFindTestHelper::testUF5(n);
// UnionFindTestHelper::testUF6(n);
// testUF123456();
testUF56();
return 0;
}
Heap 最大堆
#include<iostream>
#include<vector>
#include<string>
#include <algorithm>
#include <string>
#include <ctime>
#include <cmath>
#include <cassert>
#include <typeinfo>
using namespace std;
template<typename Item>
class MaxHeap {
private:
Item *data;
int count;
int capacity;
void shiftUp(int k) {
while (k > 1 && data[k / 2] < data[k])//k>1防止越界父节点的元素值是否小于子节点
{
swap(data[k / 2], data[k]);
k /= 2;//更新k
}
}
void shiftDown(int k) {
//判断k节点有孩子,这里判断左孩子,一棵完全二叉树中,可能只有左孩子而没有右孩子,不可能只有右孩子而没有左孩子
while (2 * k <= count) {
int j = 2 * k;//在此轮循环中,data[k]和data[j]交换位置
if (j + 1 <= count && data[j + 1] > data[j])//说明有右孩子,而且右孩子的值比左孩子的值大
{
j = j + 1;
}
// data[j] 是 data[2*k]和data[2*k+1]中的最大值
if (data[k] >= data[j])
break;
swap(data[k], data[j]);//可以优化,不用每一遍都swap,可以最后再交换(插入排序优化 思想)
k = j;
}
}
public:
//构造函数,构造一个空堆,可容纳capacity个元素
MaxHeap(int capacity) {
data = new Item[capacity + 1];//因为我们从数组下标索引1开始存数据
count = 0;
this->capacity = capacity;
}
//Heapify
MaxHeap(Item array[], int n) {
data = new Item[n + 1];
capacity = n;
for (int i = 0; i < n; i++) {
data[i + 1] == array[i];
}
count = n;
for (int i = count / 2; i >= 1; i--) {
shiftDown(i);
}
}
//析构函数
~MaxHeap() {
delete[] data;
}
//返回堆中元素的个数
int size() {
return count;
}
bool isEmpty() {
return count == 0;
}
void insert(Item item) {
assert(count + 1 <= capacity);
data[count + 1] = item;//隐藏数组越界问题,可以先判断后开辟新的空间解决
count++;
shiftUp(count);
}
void print() {
for (int i = 1; i <= size(); i++) {
cout << data[i] << " ";
}
cout << endl;
}
Item extractMax() {
assert(count > 0);
Item ret = data[1];
swap(data[1], data[count]);
count--;
shiftDown(1);
return ret;
}
public:
// 以树状打印整个堆结构
void testPrint() {
// 我们的testPrint只能打印100个元素以内的堆的树状信息
if (size() >= 100) {
cout << "This print function can only work for less than 100 int";
return;
}
// 我们的testPrint只能处理整数信息
if (typeid(Item) != typeid(int)) {
cout << "This print function can only work for int item";
return;
}
cout << "The max heap size is: " << size() << endl;
cout << "Data in the max heap: ";
for (int i = 1; i <= size(); i++) {
// 我们的testPrint要求堆中的所有整数在[0, 100)的范围内
assert(data[i] >= 0 && data[i] < 100);
cout << data[i] << " ";
}
cout << endl;
cout << endl;
int n = size();
int max_level = 0;
int number_per_level = 1;
while (n > 0) {
max_level += 1;
n -= number_per_level;
number_per_level *= 2;
}
int max_level_number = int(pow(2, max_level - 1));
int cur_tree_max_level_number = max_level_number;
int index = 1;
for (int level = 0; level < max_level; level++) {
string line1 = string(max_level_number * 3 - 1, ' ');
int cur_level_number = min(count - int(pow(2, level)) + 1, int(pow(2, level)));
bool isLeft = true;
for (int index_cur_level = 0; index_cur_level < cur_level_number; index++, index_cur_level++) {
putNumberInLine(data[index], line1, index_cur_level, cur_tree_max_level_number * 3 - 1, isLeft);
isLeft = !isLeft;
}
cout << line1 << endl;
if (level == max_level - 1)
break;
string line2 = string(max_level_number * 3 - 1, ' ');
for (int index_cur_level = 0; index_cur_level < cur_level_number; index_cur_level++)
putBranchInLine(line2, index_cur_level, cur_tree_max_level_number * 3 - 1);
cout << line2 << endl;
cur_tree_max_level_number /= 2;
}
}
private:
void putNumberInLine(int num, string &line, int index_cur_level, int cur_tree_width, bool isLeft) {
int sub_tree_width = (cur_tree_width - 1) / 2;
int offset = index_cur_level * (cur_tree_width + 1) + sub_tree_width;
assert(offset + 1 < line.size());
if (num >= 10) {
line[offset + 0] = '0' + num / 10;
line[offset + 1] = '0' + num % 10;
} else {
if (isLeft)
line[offset + 0] = '0' + num;
else
line[offset + 1] = '0' + num;
}
}
void putBranchInLine(string &line, int index_cur_level, int cur_tree_width) {
int sub_tree_width = (cur_tree_width - 1) / 2;
int sub_sub_tree_width = (sub_tree_width - 1) / 2;
int offset_left = index_cur_level * (cur_tree_width + 1) + sub_sub_tree_width;
assert(offset_left + 1 < line.size());
int offset_right = index_cur_level * (cur_tree_width + 1) + sub_tree_width + 1 + sub_sub_tree_width;
assert(offset_right < line.size());
line[offset_left + 1] = '/';
line[offset_right + 0] = '\\';
}
};
void testHeapSort() {
MaxHeap<int> maxHeap = MaxHeap<int>(100);
cout << maxHeap.size() << endl;
int n = 15;
srand(time(NULL));
for (int i = 0; i < n; i++) {
maxHeap.insert(rand() % 100);//[0,100)
}
maxHeap.print();
maxHeap.testPrint();
//while (!maxHeap.isEmpty())
//将maxHeap中的数据通过extractMax取出来,
//取出来的数据应该是从大到小顺序取出来的
int *array = new int[n];
for (int i = 0; i < n; i++) {
array[i] = maxHeap.extractMax();
cout << array[i] << " ";
}
cout << endl;
for (int i = 1; i < n; i++) {
assert(array[i - 1] >= array[i]);
}
delete[] array;
}
int main(){
testHeapSort();
std::cout<<"Hello"<<endl;
return 0;
}