C++拾遗
C++ cin.get用法
与字符串输入一样,有时候使用 cin>> 读取字符也不会按我们想要的结果行事。
因为它会忽略掉所有前导白色空格,所以使用 cin>> 就不可能仅输入一个空格或回车符。除非用户输入了空格键、制表符之外的其他字符,否则程序将不可能通过 cin 语句继续执行(一旦输入了这样的字符,在程序可以继续下一个语句之前,仍然需要按回车键)。因此,要求用户“按回车键继续”的程序,不能使用 >> 运算符只读取按回车键的行为。
在这些情况下,cin 对象有一个名为 get 的内置函数很有帮助。因为 get 函数是内置在 cin 对象中的,所以可称之为 cin 的一个成员函数。get 成员函数读取单个字符,包括任何白色空格字符。如果程序需要存储正在读取的字符,则可以通过以下任意一种方式调用 get 成员函数。
在这两个例子中,假设 cin 是正被读入字符的 char 变量的名称:
cin.get (ch);
ch = cin.get();如果程序正在使用 get 函数简单地暂停屏幕直到按回车键,并且不需要存储字符,则该函数也可以这样调用:
cin.get();请注意,在所有这 3 个编程语句中,get 函数调用的格式实际上是一样的。首先是对象的名称,在此示例中它是 cin。然后是一个句点,其后是被调用的成员函数的名称,在这里当然就是 get。语句的末尾是一组括号和一个表示结束的分号。这是调用任何成员函数的基本格式,如图 1 所示。
使用 get 成员函数的所有 3 种方式:
// This program demonstrates three ways to use cin.get()
// to pause a program.
#include <iostream>
using namespace std;
int main()
{
char ch;
cout << "This program has paused. Press Enter to continue.";
cin.get(ch);
cout << "It has paused a second time. Please press Enter again.";
ch = cin.get();
cout << "It has paused a third time. Please press Enter again.";
cin.get();
cout << "Thank you! \n";
return 0;
}This program has paused. Press Enter to continue.
It has paused a second time. Please press Enter again.
It has paused a third time. Please press Enter again.
Thank you!
--------------------------------
Process exited after 8.882 seconds with return value 0
请按任意键继续. . .
注意,在 IDE 中运行程序时,当程序终止,则输出窗口会关闭,而 cin.get 函数可用于保持输出屏幕可见。
混合使用 cin>> 和 cin.get
将 cin >> 与 cin.get 混合使用可能会导致烦人且难以发现的问题。
代码段示例:
// This program demonstrates three ways to use cin.get()
// to pause a program.
#include <iostream>
using namespace std;
int main()
{
char ch; //定义一个字符变量
int number; //定义一个整型变量
cout << "Enter a number:";
cin >> number; // 读取整数//4行
cout << "Enter a character: ";
ch = cin.get() ; // 读取字符//6行
cout << "Thank You!\n";
return 0;
}Enter a number:3
Enter a character: Thank You!
--------------------------------
Process exited after 11.77 seconds with return value 0
请按任意键继续. . .
这些语句允许用户输入一个数字,而不是一个字符。看来第 6 行的 cin.get 语句已经被跳过了。这是因为 cin>> 和 cin.get 使用略有不同的技术来读取数据。
在示例代码段中,当执行第 4 行时,用户输入一个数字,然后按回车键。假设输入的是数字 100。按回车键会导致一个换行符(‘\n’)存储在键盘缓冲区数字 100 之后,如图 2 所示。
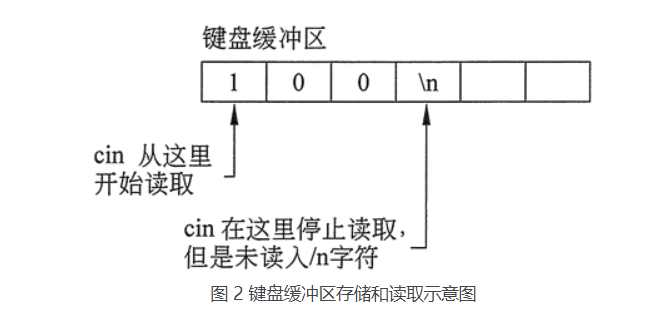
当第 4 行中的 cin>> 语句读取用户输入的数据时,它会在遇到换行符时停止。换行字符未被读取,而是仍保留在键盘缓冲区中。从键盘读取数据的输入语句只在键盘缓冲区为空时等待用户输入值,但现在不为空。
当第 6 行中的 cin.get 函数执行时,它开始从先前输入操作停止的键盘缓冲区读取,并发现了换行符,所以它无须等待用户输入另一个值。这种问题最直接的解决办法是使用 cin.ignore 函数。
不定长输入数组
#include<iostream>
#include<vector>
#include<string>
using namespace std;
int main(){
int a;
vector<int> re;
while(cin>>a){
re.push_back(a);
if(getchar()=='\n') //遇回车结束
break;
}
for(int i=0;i<re.size();i++){
cout<<re[i]<<" ";
}
std::cout<<"Hello"<<endl;
return 0;
}
C 库函数 - printf()
描述
C 库函数 int printf(const char *format, …) 发送格式化输出到标准输出 stdout。
printf()函数的调用格式为:
printf("<格式化字符串>", <参量表>);声明
下面是 printf() 函数的声明。
int printf(const char *format, ...)参数
- format – 这是字符串,包含了要被写入到标准输出 stdout 的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。format 标签属性是 %[flags][width][.precision][length]specifier,具体讲解如下:
| 格式字符 | 意义 |
|---|---|
| d | 以十进制形式输出带符号整数(正数不输出符号) |
| o | 以八进制形式输出无符号整数(不输出前缀0) |
| x,X | 以十六进制形式输出无符号整数(不输出前缀Ox) |
| u | 以十进制形式输出无符号整数 |
| f | 以小数形式输出单、双精度实数 |
| e,E | 以指数形式输出单、双精度实数 |
| g,G | 以%f或%e中较短的输出宽度输出单、双精度实数 |
| c | 输出单个字符 |
| s | 输出字符串 |
| p | 输出指针地址 |
| lu | 32位无符号整数 |
| llu | 64位无符号整数 |
| flags(标识) | 描述 |
|---|---|
| - | 在给定的字段宽度内左对齐,默认是右对齐(参见 width 子说明符)。 |
| + | 强制在结果之前显示加号或减号(+ 或 -),即正数前面会显示 + 号。默认情况下,只有负数前面会显示一个 - 号。 |
| 空格 | 如果没有写入任何符号,则在该值前面插入一个空格。 |
| # | 与 o、x 或 X 说明符一起使用时,非零值前面会分别显示 0、0x 或 0X。 与 e、E 和 f 一起使用时,会强制输出包含一个小数点,即使后边没有数字时也会显示小数点。默认情况下,如果后边没有数字时候,不会显示显示小数点。 与 g 或 G 一起使用时,结果与使用 e 或 E 时相同,但是尾部的零不会被移除。 |
| 0 | 在指定填充 padding 的数字左边放置零(0),而不是空格(参见 width 子说明符)。 |
| width(宽度) | 描述 |
|---|---|
| (number) | 要输出的字符的最小数目。如果输出的值短于该数,结果会用空格填充。如果输出的值长于该数,结果不会被截断。 |
| * | 宽度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| .precision(精度) | 描述 |
|---|---|
| .number | 对于整数说明符(d、i、o、u、x、X):precision 指定了要写入的数字的最小位数。如果写入的值短于该数,结果会用前导零来填充。如果写入的值长于该数,结果不会被截断。精度为 0 意味着不写入任何字符。 对于 e、E 和 f 说明符:要在小数点后输出的小数位数。 对于 g 和 G 说明符:要输出的最大有效位数。 对于 s: 要输出的最大字符数。默认情况下,所有字符都会被输出,直到遇到末尾的空字符。 对于 c 类型:没有任何影响。 当未指定任何精度时,默认为 1。如果指定时不带有一个显式值,则假定为 0。 |
| .* | 精度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| length(长度) | 描述 |
|---|---|
| h | 参数被解释为短整型或无符号短整型(仅适用于整数说明符:i、d、o、u、x 和 X)。 |
| l | 参数被解释为长整型或无符号长整型,适用于整数说明符(i、d、o、u、x 和 X)及说明符 c(表示一个宽字符)和 s(表示宽字符字符串)。 |
| L | 参数被解释为长双精度型(仅适用于浮点数说明符:e、E、f、g 和 G)。 |
- 附加参数 – 根据不同的 format 字符串,函数可能需要一系列的附加参数,每个参数包含了一个要被插入的值,替换了 format 参数中指定的每个 % 标签。参数的个数应与 % 标签的个数相同。
返回值
如果成功,则返回写入的字符总数,否则返回一个负数。
sizeof与strlen
sizeof与strlen是有着本质的区别,sizeof是求数据类型所占的空间大小,而strlen是求字符串的长度,字符串以/0结尾。区别如下:
(1) sizeof是一个C语言中的一个单目运算符,而strlen是一个函数,用来计算字符串的长度。
(2)sizeof求的是数据类型所占空间的大小,而strlen是求字符串的长度
实例1:
printf("char=%d/n",sizeof(char)); //1
printf("char*=%d/n",sizeof(char*)); //4
printf("int=%d/n",sizeof(int)); //4
printf("int*=%d/n",sizeof(int*)); //4
printf("long=%d/n",sizeof(long)); //4
printf("long*=%d/n",sizeof(long*)); //4
printf("double=%d/n",sizeof(double)); //8
printf("double*=%d/n",sizeof(double*)); //4可以看到,char占1个字节,int占4个字节,long点4个字节,而double占8个字节。但 char*,int*,long*,double*都占4个字节的空间。
这是为什么呢?
在C语言中,char,int,long,double这些基本数据类型的长度是由编译器本身决定的。而char*,int*,long*,double*这些都是指针,回想一下,指针就是地址呀,所以里面放的都是地址,而地址的长度当前是由地址总线的位数决定的,现在的计算机一般都是32位的地址总线,也就占4个字节。
实例2:
char a[]="hello";
char b[]={'h','e','l','l','o'};
strlen(a),strlen(b)的值分别是多少?
前面分析过,strlen是求字符串的长度,字符串有个默认的结束符/0,这个结束符是在定义字符串的时候系统自动加上去的,就像定义数组a一样。数组a定义了一个字符串,数组b定义了一个字符数组。因此,strlen(a)=5,而strlen(b)的长度就不确定的,因为strlen找不到结束符。
一个比较经典的例子,分析一下:
char *c="abcdef";
char d[]="abcdef";
char e[]={'a','b','c','d','e','f'};
printf("%d%d/n",sizeof(c),strlen(c));
printf("%d%d/n",sizeof(d),strlen(d));
printf("%d%d/n",sizeof(e),strlen(e));输出的结果是:
4 6
7 6
6 14分析一下:
第一行定义c为一个字符指针变量,指向常量字符串,c里面存放的是字符串的首地址。
第二行定义d为一个字符数组,以字符串的形式给这个字符数组赋值。
第三行定义的也是个字符数组,以单个元素的形式赋值。
当以字符串赋值时,”abcdef”,结尾自动加一个”/0”.
strlen(c)遇到/0就会结束,求的是字符串的长度,为6.
sizeof(c)求的是类型空间大小,在前面说过,指针型所点的空间大小是4个字节,系统地址总线长度为32位时。
strlen(d)也是一样,字符串赋值,自动添加/0,求字符串的长度当然是6.
sizeof(d)是求这个数组所占空间的大小,即数组所占内存空间的字节数,应该为7.
sizeof(e), 数组e以单个元素赋值,没有/0结束符,所以所占空间的大小为6个字节。
strlen(e),去找/0结尾的字符串的长度,由于找不到/0,所以返回的值是一个不确定的值。
覆盖 重写 重载
1、覆盖
覆盖也称为重写(override)。
覆盖是存在类中,子类重写从基类继承过来的函数,函数名、返回值、参数列表都必须和基类相同。
当子类的对象调用成员函数的时候,如果成员函数有被覆盖则调用子类中覆盖的版本,否则调用从基类继承过来的函数。
如果子类覆盖的是基类的虚函数,则可以用来实现多态。当子类重新定义基类的虚函数之后,基类指针可以根据赋给它不同子类指针动态的调用子类中的虚函数,做到动态绑定,这就是多态。
2、重载
重载指允许在相同作用域中存在多个同名的函数,这些函数的参数表不同,编译器根据函数不同的形参表对同名函数的名称做修饰,然后这些同名函数就成了不同的函数。如:
void Fun(int a);
void Fun(double a);
void Fun(int a, int b);
void Fun(double a, int b);重载要求参数列表必须不同,比如参数类型不同、参数个数不同、参数顺序不同。如果仅仅是函数的返回值不同是没办法重载的。如:
int Fun(int a)
void Fun(int a)函数被C++编译后在符号库中的名字与C语言的不同。假设某个函数的原型为:
void foo( int x, int y);该函数被C编译器编译后在符号库中的名字为_foo;而C++编译器则会产生像_foo_int_int之类的名字。
这样的名字包含了函数名、函数参数数量及类型信息,C++就是靠这种机制来实现函数重载的。
3、重载与覆盖的区别
- 重载要求函数名相同,但是参数列表必须不同;覆盖要求函数名、参数列表、返回值必须相同。
- 重载描述的是同一个类中不同成员函数之间的关系;覆盖是子类和基类之间不同成员函数之间的关系。
- 重载的确定是在编译时确定,是静态的;虚函数则是在运行时动态确定。
在C++语言中有一组基础的概念一直都容易混淆:Overload、Override和Overwrite分别表示什么意思?下面把这三个概念整理一下:
1. Overload(重载)
重载的概念最好理解,在同一个类声明范围中,定义了多个名称完全相同、参数(类型或者个数)不相同的函数,就称之为Overload(重载)。重载的特征如下:
(1)相同的范围(在同一个类中);
(2)函数名字相同;
(3)参数不同;
(4)virtual 关键字可有可无。
2. Override(覆盖)
覆盖的概念其实是用来实现C++多态性的,即子类重新改写父类声明为virtual的函数。Override(覆盖)的特征如下:
(1)不同的范围(分别位于派生类与基类);
(2)函数名字相同;
(3)参数列表完全相同;
(4)基类函数必须有virtual 关键字。
3. Overwrite(改写)
改写是指派生类的函数屏蔽(或者称之为“隐藏”)了与其同名的基类函数。正是这个C++的隐藏规则使得问题的复杂性陡然增加,这里面分为两种情况讨论:
(1)如果派生类的函数与基类的函数同名,但是参数不同。那么此时,不论有无virtual关键字,基类的函数将被隐藏(注意别与重载混淆)。
(2)如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual关键字。那么此时,基类的函数被隐藏(注意别与覆盖混淆)。
借鉴一个网上的例子来看Overwrite(改写)的情况:
#include <iostream>
using namespace std;
class Base
{
public:
virtual void f(float x){ cout << "Base::f(float) " << x << endl; }
virtual void g(float x){ cout << "Base::g(float) " << x << endl; }
void h(float x){ cout << "Base::h(float) " << x << endl; }
};
class Derived : public Base
{
public:
virtual void f(float x){ cout << "Derived::f(float) " << x << endl; }
virtual void g(int x){ cout << "Derived::g(int) " << x << endl; }
void h(float x){ cout << "Derived::h(float) " << x << endl; }
};
int main()
{
Derived d;
Base *pb = &d;
Derived *pd = &d;
// Good : behavior depends solely on type of the object
pb->f(3.14f); // Derived::f(float) 3.14
pd->f(3.14f); // Derived::f(float) 3.14
// Bad : behavior depends on type of the pointer
pb->g(3.14f); // Base::g(float) 3.14 (surprise!)
pd->g(3.14f); // Derived::g(int) 3
// Bad : behavior depends on type of the pointer
pb->h(3.14f); // Base::h(float) 3.14 (surprise!)
pd->h(3.14f); // Derived::h(float) 3.14
return 0;
}在上面这个例子中:
- 函数Derived::f(float)覆盖(override)了Base::f(float)。
- 函数Derived::g(int)改写/隐藏(overwrite)了Base::g(float)。
- 函数Derived::h(float)改写/隐藏(overwrite)了Base::h(float)。
4. 特殊情况说明
除了上面讲到的三种情况之外,还有一些比较容易迷惑的地方,例如:
4.1 同名的普通函数与const函数本质上是两个不同的函数,应该等价理解为这两个同名函数的参数是不同的。在派生类中的virtual函数理解上可能会有误解。
参见如下例子:
#include <iostream>
using namespace std;
class Base
{
public:
virtual void f(float x){ cout << "Base::f(float) " << x << endl; }
};
class Derived : public Base
{
public:
virtual void f(float x) const { cout << "Derived::f(float) " << x << endl; }
};
int main()
{
Derived d;
Base *pb = &d;
Derived *pd = &d;
// Bad : behavior depends solely on type of the object
pb->f(3.14f); // Base::f(float) 3.14
pd->f(3.14f); // Derived::f(float) 3.14
return 0;
}4.2 基类中定义的virtual虚函数,在继承子类中同名函数自动都属于虚函数,可以不需要virtual关键字。
4.3 如果基类中定义的函数不是virtual,而子类中又将相同函数定义为virtual,则称之为越位,函数行为依赖于指针/引用的类型,而不是实际对象的类型。
参见如下例子:
#include<iostream>
using namespace std;
class Base
{
public:
void f(){ cout << "Base::f() " << endl; }
virtual void g(){ cout << "Base::g() " << endl; }
};
class Derived : public Base
{
public:
virtual void f(){ cout << "Derived::f() " << endl; }
void g(){ cout << "Derived::g() " << endl; }
};
class VirtualDerived : virtual public Base
{
public:
void f(){ cout << "VirtualDerived::f() " << endl; }
void g(){ cout << "VirtualDerived::g() " << endl; }
};
int main()
{
Base *d = new Derived;
Base *vd = new VirtualDerived;
d->f(); // Base::f() Bad behavior
d->g(); // Derived::g()
vd->f(); // Base::f() Bad behavior
vd->g(); // VirtualDerived::g()
delete d;
delete vd;
return 0;
}5. 针对非虚函数的继承说明
在《Effective C++》中讲述了这样一个规则:任何条件下都要禁止重新定义继承而来的非虚函数。
公有继承的含义是 “是一个”(is a),”在一个类中声明一个非虚函数实际上为这个类建立了一种特殊性上的不变性”。如果将这些分析套用到类B、类D和非虚成员函数B::mf,那么:
(1)适用于B对象的一切也适用于D对象,因为每个D的对象“是一个”B的对象。
(2)B的子类必须同时继承mf的接口和实现,因为mf在B中是非虚函数。
那么,如果D重新定义了mf,设计中就会产生矛盾。如果D真的需要实现和B不同的mf,而且每个B的对象(无论怎么特殊)也真的要使用B实现的mf,那么每个D将不 “是一个” B。这种情况下,D不能从B公有继承。相反,如果D真的必须从B公有继承,而且D真的需要和B不同的mf的实现,那么,mf就没有为B反映出特殊性上的不变性。这种情况下,mf应该是虚函数。最后,如果每个D真的 “是一个” B,并且如果mf真的为B建立了特殊性上的不变性,那么,D实际上就不需要重新定义mf,也就决不能这样做。
不管采用上面的哪一种论据都可以得出这样的结论:任何条件下都要禁止重新定义继承而来的非虚函数。