C++
C++类
类成员的可见性
类成员有三种访问控制修饰符,每个成员只能选择其中之一
private:私有成员只允许本类的成员函数访问,对类外部不可见。数据成员往往作为私有成员
protect:保护成员能被本类成员函数访问,也能被派生类访问
public :公有成员对类外可见,类内部也能访问。公有成员作为该类对象的操作接口,使类外程序能操作对象。成员函数一般作为公有成员
一个类中的多个成员函数可重载(overload),即函数名相同,但形参个数或类型须要不同。一个函数名及其形参作为一个整体称为该函数的基调或特征(signature),一个类中的各个成员函数应具有不同的基调
结构与类的区别是类成员缺省为私有private,而结构成员缺省为公有public
构造函数
构造函数(constructor) 是一种特殊的函数,其作用是在创建对象时由系统来调用,对新建对象的状态进行初始化。
构造函数特性:
一、名字必须与类名相同
二、不指定返回值类型
三、可以无参数,也可以有多个形参。利用不同形参,一个类中可重载定义多个构造函数
四、创建一个对象时,系统会根据实参自动调用某个构造函数
缺省构造函数
每个函数都应该有构造函数,否则就不能实例化创建对象。如果一个类中没有显式定义任何构造函数,编译器就自动生成一个无参的公有的构造函数,该构造函数就是一个缺省构造函数(default constructor)
类中也可以显式定义一个缺省构造函数。如果 一个构造函数无参,或有参但所有形参都是缺省值,它也是一个缺省构造函数。
委托构造函数
同一个类中往往有多个构造函数。如果多个构造函数具有一些共同行为,应避免重复编码。
通常有两个办法,一个办法就是建立一个成员函数,让多个构造函数来调用;另一个办法就是C++11引入的委托构造函数(delegating constructor)
C++11之前的构造函数中不能调用本类其他构造函数,而委托构造函数是能调用本类其他构造函数的构造函数。被调用的构造函数称为目标构造函数(target constructor)。委托构造函数的语法形式:
<类名> (形参表):*<类名> (实参表)* {函数体}
其中斜体部分确定调用另一个构造函数(注意实参表编码应避免调用自己),即先按实参表调用构造函数,然后再执行自己的函数体。
委托构造函数有两个限制:一是不能做成员初始化,但可以在函数体中对成员初始化;(这句话有点矛盾,感觉应该是不能使用成员初始化列表,会与使用目标构造函数冲突),二是函数体中不能调用目标构造函数。
class X{
int type = 1;
char name = 'a';
void initRset(){/*其他初始化*/}//class默认为私有,私有成员函数
public:
X(){initRset();}//目标构造函数
X(int x):X(){type = x;}//委托构造函数1
X(char e):X(){name = e}//委托构造函数2
};上面程序中,第一个构造函数调用私有成员函数initRset();第二个构造函数是委托构造函数,先调用第一个构造函数,然后在函数体中对type成员初始化;第三个构造函数也是委托构造函数,先调用第一个构造函数,然后在函数体中对name成员初始化。这两个委托构造函数体中包含数据成员的初始化,不能移到成员初始化表中。
设计私有的目标构造函数,使委托构造函数得到简化:
class X{
int type = 1;
char name = 'a';
X(int i ,char e) :type(i),name(e){/*其他初始化*/}//私有目标构造函数
public:
X():X(1,'a'){}//委托构造函数1
X(int x):X(x,'a'){}//委托构造函数2
X(char e):X(1,e){}//委托构造函数3
};委托构造函数自己也可能作为目标构造函数。修改无参构造函数如下:
X():X(1){}//调用下一个
X(int x):X(x,'a'){}//目标函数,同时也是委托构造函数
//这样就形成一种链式委托构造,但要注意避免形成委托环(delegation cycle)析构函数
析构函数(destructor)与构造函数的作用相反,用来完成对象被撤销前的扫尾清理工作。析构函数是在撤销对象前由系统自动调用的。析构函数执行后,系统回收该对象的存储空间。该对象的生命周期也就结束了
析构函数的特性:
一、析构函数名是在类名前加~构成,该符号曾作为按位求反的单目运算符
二、不指定返回类型
三、析构函数没有形参,因此不能被重载定义,即一个类只能有一个析构函数
四、在撤销一个对象时系统将自动调用析构函数,该对象作为析构函数的当前对象
五、如果没有显式定义析构函数,编译器将生成一个公有的析构函数,成为缺省析构函数,函数体为空
要执行对象的析构函数情形
一、当程序执行离开局部对象所在作用域时,要撤销局部对象;当程序完成时,要撤销全局对象和静态对象
二、用delete回收先前用new创建的对象
三、临时匿名对象使用完毕
四、显式调用析构函数~A();仅用于特殊条件下,比如exit(1)之前
何时需要自定义析构函数?
如果类的数据成员中含有指针,而且在构造函数中用new来动态申请内存,此时就需要自定义析构函数,用delete来动态回收内存。此时也要求自行定义拷贝构造函数和拷贝赋值函数
拷贝构造函数
一个类不仅自动生成缺省构造函数,还会生成拷贝构造函数和拷贝赋值函数(依据C++11/C++14)
创建一个对象有两种来源:要么是从类中创建而来,要么是从一个已有的同类对象复制而来,也就是克隆对象。后者需要调用拷贝构造函数。
拷贝构造函数(copy constructor)是一种特殊的构造函数,用一个已有的同类对象来初始化新建对象,并复制器非静态数据成员。拷贝构造函数有一个特殊的形参,格式如下
<类名> (const <类名> & <对象名>):成员初始化表{函数体}拷贝构造函数只有一个形参,就是同类对象的左值引用,其中修饰词const表示函数体中不能改变被复制对象的状态
每个类中都有一个拷贝构造函数。如果类中没有显式定义拷贝构造函数,编译器就自动生成一个公有的拷贝构造函数,而且函数体中自动复制非静态数据成员到新建对象
会执行拷贝构造函数的情形
一、用说明语句来创建一个对象时,用一个已有对象来初始化新建对象
二、调用某个函数时,以值传递一个命名对象。但如果实参是匿名对象,则仅执行构造函数而不执行拷贝构造函数。
三、函数返回一个对象时,如果返回匿名对象,不执行拷贝构造函数。但若返回命名对象,是否执行拷贝构造函数与编译优化选项有关。
如果一个类中仅显示定义拷贝构造函数,没有定义其他构造函数,该类不能创建对象,此时编译器不会生成缺省构造函数,即该类不能创建对象。
拷贝赋值函数
用赋值语句把一个对象赋值给另一个已有的同类对象时,将调用该类的拷贝赋值函数,全名是copy-assignment operator(拷贝赋值运算符)
该函数一般格式如下:
<类名> &operator = (const <类名>&<对象名>){
//函数体
return *this;
}拷贝构造函数的特性
一、函数名为 operator=,是一种特殊的运算符重载函数
二、有一个形参,该类对象的常量是左值引用(与拷贝构造函数一样)
三、拷贝赋值函数是一个成员函数,而不是构造函数,因此必须说明其返回类型。其返回值是赋值语句的做值对象引用,就是赋值运算符”=”左边的对象。函数体中返回语句一般都是” return *this”。在赋值语句中左值对象就是当前对象,右值对象就是函数调用的实参
四、如果类中未显示定义拷贝赋值函数,编译器就会自动生成一个公有的拷贝赋值函数,函数体中将复制所有非静态数据成员,就像缺省拷贝构造函数。
拷贝赋值函数与拷贝构造函数功能相似,极易混淆。赋值操作是将一个已有对象赋值给另一个已有同类对象,而拷贝构造函数则要创建一个新对象
当赋值语句中对象作为赋值的左值,且右值是同类对象表达式时,将调用拷贝赋值函数
深拷贝与浅拷贝
一般来说,如果类中有指针数据成员,而且在构造函数中用new来动态申请内存,那么在对象撤销是就要用delete来回收内存。对于这样的对象,如果调用了缺省提供的拷贝构造函数或者拷贝赋值函数,就会导致多个对象的指针成员指向同一块内存空间。这种拷贝仅拷贝外层对象,成为浅拷贝
当这种对象撤销是,析构函数分别执行就会使同一块内存被回收多次,导致运行错误。要避免这种错误,就要显示定义拷贝构造函数和拷贝赋值函数,避免复制指针成员,而是拷贝动态内容。这种拷贝将拷贝内层对象,称为深拷贝
如果一个类型显示定义拷贝构造函数和拷贝赋值函数,该类称为可拷贝(copyable)类型
#include<iostream>
#include<cmath>
#include<string>
#include<cstring>
using namespace std;
class Person{
char *name;//指针成员
char sex;
public:
//构造函数
Person(char* name,char sex):sex(sex),name(nullptr){
setName(name);//调用成员函数来设置姓名
}
//析构函数,回收动态内存
~Person(){
if(name!=nullptr)
delete [] name;
}
//拷贝构造函数,委托构造
Person(const Person &p):Person(p.name,p.sex){
}
//拷贝赋值函数
Person& operator = (const Person &p){
setName(p.name);
sex = p.sex;
return *this;
}
//设置姓名
void setName(const char* p){
if(name!=nullptr)
delete [] name;//如果原先有名字,先撤销原名
if(p!=nullptr){
name = new char[strlen(p)+1];//根据新名申请一块空间
strcpy(name,p);//赋值新名
} else{
name = nullptr;
}
}
//const 防止人名被随意更改
const char* getName(){
if(name==nullptr)
return "unnamed";
return name;
}
char getSex(){
return sex;
}
void show(){
cout<<(sex=='f'?"She is":"He is ")<<getName()<<endl;
}
};
int main(){
char n1[] = "tony";
Person a(n1,'m');
a.show();
Person b=a;//调用拷贝构造函数
char n2[] = "lusy";
b.setName(n2);
b.show();
a=b;//调用拷贝赋值
a.show();
return 0 ;
} 可以采用string类型来表示,这样就无需指针成员,也就避免了自行定义的析构函数、拷贝构造函数和拷贝赋值函数
#include<iostream>
#include<cmath>
#include<string>
using namespace std;
class Person{
string name;//指针成员
char sex;
public:
//构造函数
Person(string name,char sex):sex(sex),name(""){
setName(name);//调用成员函数来设置姓名
}
//析构函数
~Person(){
}
//设置姓名
void setName(const string& p){
name = p;
}
//const 防止人名被随意更改
const string getName(){
return name;
}
char getSex(){
return sex;
}
void show(){
cout<<(sex=='f'?"She is":"He is ")<<getName()<<endl;
}
};
int main(){
string n1= "tony";
Person a(n1,'m');
a.show();
Person b=a;//调用拷贝构造函数
string n2 = "lusy";
b.setName(n2);
b.show();
a=b;//调用拷贝赋值
a.show();
return 0 ;
} 转换构造函数
转换构造函数(conversion constructor) 持有单个形参,且形参类型不同与本类,可实现隐式的自动类型转换,将其他类型的数据转换为本类对象
#include<iostream>
#include<cmath>
#include<string>
using namespace std;
class Integer{
int value;
public:
//缺省构造函数,同时也是转换构造函数
Integer(int x){
value = x;
cout<<"Constructor of"<<value<<endl;
}
//拷贝构造函数
Integer(const Integer& i){
value = i.value;
cout<<"Copy constructor of"<<value<<endl;
}
Integer& operator =(const Integer& a){
value = a.value;
cout<<"operator = "<<value<<endl;
return *this;
}
int getValue(){
return value;
}
};
void fun(Integer a){
cout<<a.getValue()<<endl;
}
int main(){
Integer i1 = 10;//A 等价于Integer i1(10)
Integer i2 = 10+20;//B 等价于Integer i2 (10+20)
fun(40);//C
i2 = 60;//D
} Constructor of10
Constructor of30
Constructor of40
40
Constructor of60
operator = 60A行和B行调用了转换构造函数,输出前两行。只要赋值符号左边是一个对象,右边是转换构造函数的形参类型的一个对象或值,系统就会自动调用该函数
C行调用fun函数,该函数的形参是Integer类型,而实参为一个int值,此时就自动调用转换构造函数,创建一个对象,输出第三行,第四行
D行是一条赋值语句,但又包含了创建对象,等价于i2=Integer(60);即先调用转换构造函数创建一个临时对象,在调用拷贝赋值函数赋值给对象i2,然后临时对象别撤销
移动构造函数
移动赋值函数
类的继承
类的继承后方法属性变化:
private 属性不能够被继承。
使用private继承,父类的protected和public属性在子类中变为private;
使用protected继承,父类的protected和public属性在子类中变为protected;
使用public继承,父类中的protected和public属性不发生改变;
private, public, protected 访问标号的访问范围:
private:只能由1.该类中的函数、2.其友元函数访问。
不能被任何其他访问,该类的对象也不能访问。
protected:可以被1.该类中的函数、2.子类的函数、以及3.其友元函数访问。
但不能被该类的对象访问。
public:可以被1.该类中的函数、2.子类的函数、3.其友元函数访问,也可以由4.该类的对象访问。
注:友元函数包括3种:设为友元的普通的非成员函数;设为友元的其他类的成员函数;设为友元类中的所有成员函数。
- 继承方式;
- 基类成员的访问权限(即public/private/protected)。
继承有三种方式,即公有(Public)继承、私有(Private)继承、保护(Protected)继承。(私有成员不能被继承)
- 公有继承就是将基类的公有成员变为自己的公有成员,基类的保护成员变为自己的保护成员。
- 保护继承是将基类的公有成员和保护成员变成自己的保护成员。
- 私有继承是将基类的公有成员和保护成员变成自己的私有成员。
智能指针
这三个智能指针模板(auto_ptr、unique_ptr和share_ptr)都定义类似指针的对象,可以将new获得(直接或间接)的地址赋给这种对象。当智能指针过期,其析构函数将使用delete来释放内存。因此,如果将new返回的地址复制给这些对象,将无需记住稍后释放这些内存:在智能指针过期时,这些内存将自动被释放。
C++里面的四个智能指针: auto_ptr, shared_ptr, weak_ptr, unique_ptr 其中后三个是c++11支持,并且第一个已经被11弃用。
为什么要使用智能指针:
智能指针的作用是管理一个指针,因为存在以下这种情况:申请的空间在函数结束时忘记释放,造成内存泄漏。使用智能指针可以很大程度上的避免这个问题,因为智能指针就是一个类,当超出了类的作用域是,类会自动调用析构函数,析构函数会自动释放资源。所以智能指针的作用原理就是在函数结束时自动释放内存空间,不需要手动释放内存空间。
1.auto_ptr(c++98的方案,cpp11已经抛弃)
采用所有权模式。
auto_ptr< string> p1 (new string ("I reigned lonely as a cloud.”));
auto_ptr<string> p2;
p2 = p1; //auto_ptr不会报错.此时不会报错,p2剥夺了p1的所有权,但是当程序运行时访问p1将会报错。所以auto_ptr的缺点是:存在潜在的内存崩溃问题!
2.unique_ptr(替换auto_ptr)
unique_ptr实现独占式拥有或严格拥有概念,保证同一时间内只有一个智能指针可以指向该对象。它对于避免资源泄露(例如“以new创建对象后因为发生异常而忘记调用delete”)特别有用。
采用所有权模式,还是上面那个例子
unique_ptr<string> p3 (new string ("auto")); //#4
unique_ptr<string> p4; //#5
p4 = p3;//此时会报错!!编译器认为p4=p3非法,避免了p3不再指向有效数据的问题。因此,unique_ptr比auto_ptr更安全。
另外unique_ptr还有更聪明的地方:当程序试图将一个 unique_ptr 赋值给另一个时,如果源 unique_ptr 是个临时右值,编译器允许这么做;如果源 unique_ptr 将存在一段时间,编译器将禁止这么做,比如:
unique_ptr<string> pu1(new string ("hello world"));
unique_ptr<string> pu2;
pu2 = pu1; // #1 not allowed
unique_ptr<string> pu3;
pu3 = unique_ptr<string>(new string ("You")); // #2 allowed其中#1留下悬挂的unique_ptr(pu1),这可能导致危害。而#2不会留下悬挂的unique_ptr,因为它调用 unique_ptr 的构造函数,该构造函数创建的临时对象在其所有权让给 pu3 后就会被销毁。这种随情况而已的行为表明,unique_ptr 优于允许两种赋值的auto_ptr 。
注:如果确实想执行类似与#1的操作,要安全的重用这种指针,可给它赋新值。C++有一个标准库函数std::move(),让你能够将一个unique_ptr赋给另一个。例如:
unique_ptr<string> ps1, ps2;
ps1 = demo("hello");
ps2 = move(ps1);
ps1 = demo("alexia");
cout << *ps2 << *ps1 << endl;3.shared_ptr
shared_ptr实现共享式拥有概念。多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用被销毁”时候释放。从名字share就可以看出了资源可以被多个指针共享,它使用计数机制来表明资源被几个指针共享。可以通过成员函数use_count()来查看资源的所有者个数。除了可以通过new来构造,还可以通过传入auto_ptr, unique_ptr,weak_ptr来构造。当我们调用release()时,当前指针会释放资源所有权,计数减一。当计数等于0时,资源会被释放。
shared_ptr 是为了解决 auto_ptr 在对象所有权上的局限性(auto_ptr 是独占的), 在使用引用计数的机制上提供了可以共享所有权的智能指针。
成员函数:
use_count 返回引用计数的个数
unique 返回是否是独占所有权( use_count 为 1)
swap 交换两个 shared_ptr 对象(即交换所拥有的对象)
reset 放弃内部对象的所有权或拥有对象的变更, 会引起原有对象的引用计数的减少
get 返回内部对象(指针), 由于已经重载了()方法, 因此和直接使用对象是一样的.如 shared_ptr
4.weak_ptr
weak_ptr 是一种不控制对象生命周期的智能指针, 它指向一个 shared_ptr 管理的对象. 进行该对象的内存管理的是那个强引用的 shared_ptr. weak_ptr只是提供了对管理对象的一个访问手段。weak_ptr 设计的目的是为配合 shared_ptr 而引入的一种智能指针来协助 shared_ptr 工作, 它只可以从一个 shared_ptr 或另一个 weak_ptr 对象构造, 它的构造和析构不会引起引用记数的增加或减少。weak_ptr是用来解决shared_ptr相互引用时的死锁问题,如果说两个shared_ptr相互引用,那么这两个指针的引用计数永远不可能下降为0,资源永远不会释放。它是对对象的一种弱引用,不会增加对象的引用计数,和shared_ptr之间可以相互转化,shared_ptr可以直接赋值给它,它可以通过调用lock函数来获得shared_ptr。
#include<iostream>
#include<vector>
#include<string>
#include<memory>>
class B;
class A
{
public:
shared_ptr<B> pb_;
~A()
{
cout<<"A delete\n";
}
};
class B
{
public:
shared_ptr<A> pa_;
~B()
{
cout<<"B delete\n";
}
};
void fun()
{
shared_ptr<B> pb(new B());
shared_ptr<A> pa(new A());
pb->pa_ = pa;
pa->pb_ = pb;
cout<<pb.use_count()<<endl;
cout<<pa.use_count()<<endl;
}
int main()
{
fun();
return 0;
}2
2
可以看到fun函数中pa ,pb之间互相引用,两个资源的引用计数为2,当要跳出函数时,智能指针pa,pb析构时两个资源引用计数会减一,但是两者引用计数还是为1,导致跳出函数时资源没有被释放(A B的析构函数没有被调用),如果把其中一个改为weak_ptr就可以了,我们把类A里面的shared_ptr pb_; 改为weak_ptr pb_; 运行结果如下,这样的话,资源B的引用开始就只有1,当pb析构时,B的计数变为0,B得到释放,B释放的同时也会使A的计数减一,同时pa析构时使A的计数减一,那么A的计数为0,A得到释放。
#include<iostream>
#include<vector>
#include<string>
#include<memory>>
using namespace std;
class B;
class A
{
public:
weak_ptr<B> pb_;
~A()
{
cout<<"A delete\n";
}
};
class B
{
public:
shared_ptr<A> pa_;
~B()
{
cout<<"B delete\n";
}
};
void fun()
{
shared_ptr<B> pb(new B());
shared_ptr<A> pa(new A());
pb->pa_ = pa;
pa->pb_ = pb;
cout<<pb.use_count()<<endl;
cout<<pa.use_count()<<endl;
}
int main()
{
fun();
return 0;
}
1
2
B delete
A delete注意的是我们不能通过weak_ptr直接访问对象的方法,比如B对象中有一个方法print(),我们不能这样访问,pa->pb_->print(); 英文pb_是一个weak_ptr,应该先把它转化为shared_ptr,如:shared_ptr p = pa->pb_.lock(); p->print();
智能指针主要用于管理在堆上分配的内存,它将普通的指针封装为一个栈对象。当栈对象的生存周期结束后,会在析构函数中释放掉申请的内存,从而防止内存泄漏。C++ 11中最常用的智能指针类型为shared_ptr,它采用引用计数的方法,记录当前内存资源被多少个智能指针引用。该引用计数的内存在堆上分配。当新增一个时引用计数加1,当过期时引用计数减一。只有引用计数为0时,智能指针才会自动释放引用的内存资源。对shared_ptr进行初始化时不能将一个普通指针直接赋值给智能指针,因为一个是指针,一个是类。可以通过make_shared函数或者通过构造函数传入普通指针。并可以通过get函数获得普通指针。
请你回答一下智能指针有没有内存泄露的情况
参考回答:
当两个对象相互使用一个shared_ptr成员变量指向对方,会造成循环引用,使引用计数失效,从而导致内存泄漏。例如:
上述代码中,parent有一个shared_ptr类型的成员指向孩子,而child也有一个shared_ptr类型的成员指向父亲。然后在创建孩子和父亲对象时也使用了智能指针c和p,随后将c和p分别又赋值给child的智能指针成员parent和parent的智能指针成员child。从而形成了一个循环引用:
请你来说一下智能指针的内存泄漏如何解决
参考回答:
为了解决循环引用导致的内存泄漏,引入了weak_ptr弱指针,weak_ptr的构造函数不会修改引用计数的值,从而不会对对象的内存进行管理,其类似一个普通指针,但不指向引用计数的共享内存,但是其可以检测到所管理的对象是否已经被释放,从而避免非法访问。
要创建智能指针对象,必须包含头文件memory
// auto_ptr example
#include <iostream>
#include <memory>
int main () {
std::auto_ptr<int> p1 (new int);
*p1.get()=10;
std::auto_ptr<int> p2 (p1);
std::cout << "p2 points to " << *p2 << '\n';
// (p1 is now null-pointer auto_ptr)
return 0;
}Output:
p2 points to 10/*
std::auto_ptr::get
Get pointer
Returns a pointer to the object pointed by the auto_ptr object, if any, or zero if it does not point to any object.
Parameters
none
Return value
A pointer to the element pointed by the auto_ptr object.
If the auto_ptr object is not pointing to any object, a zero-value is returned.
X is auto_ptr's template parameter (i.e., the type pointed).
*/
// auto_ptr::get example
#include <iostream>
#include <memory>
,
int main () {
std::auto_ptr<int> p (new int);
*p.get() = 100;
std::cout << "p points to " << *p.get() << '\n';
return 0;
}Output:
p points to 100// auto_ptr::operator* example
#include <iostream>
#include <memory>
int main () {
std::auto_ptr<int> p1 (new int (10));
std::auto_ptr<int> p2 (new int);
*p2 = *p1 * 2;
std::cout << "p1 points to: " << *p1 << '\n';
std::cout << "p2 points to: " << *p2 << '\n';
return 0;
}Output:
p1 points to: 10
p2 points to: 20/ auto_ptr::operator-> example
#include <iostream>
#include <cstddef>
#include <memory>
int main () {
typedef std::pair<int*,std::ptrdiff_t> mypair;
std::auto_ptr<mypair> p (new mypair);
*p = std::get_temporary_buffer<int>(5);
if (p->second >= 5) {
for (int i=0; i<5; i++)
p->first[i]=i*5;
for (int i=0; i<5; i++)
std::cout << p->first[i] << " ";
std::cout << '\n';
}
std::return_temporary_buffer (p->first);
return 0;
}Output:
0 5 10 15 20
// auto_ptr::operator= example
#include <iostream>
#include <memory>
int main () {
std::auto_ptr<int> p;
std::auto_ptr<int> p2;
p = std::auto_ptr<int> (new int);
*p = 11;
p2 = p;
std::cout << "p2 points to " << *p2 << '\n';
// (p is now null-pointer auto_ptr)
return 0;
}Output:
p2 points to 11
// auto_ptr::release example
#include <iostream>
#include <memory>
int main () {
std::auto_ptr<int> auto_pointer (new int);
int * manual_pointer;
*auto_pointer=10;
manual_pointer = auto_pointer.release();
std::cout << "manual_pointer points to " << *manual_pointer << '\n';
// (auto_pointer is now null-pointer auto_ptr)
delete manual_pointer;
return 0;
}Output:
manual_pointer points to 10
/*Deallocate object pointed and set new value
Destructs the object pointed by the auto_ptr object, if any, and deallocates its memory (by calling operator delete). If a value for p is specified, the internal pointer is initialized to that value (otherwise it is set to the null pointer).
To only release the ownership of a pointer without destructing the object pointed by it, use member function release instead.*/
// auto_ptr::reset example
#include <iostream>
#include <memory>
int main () {
std::auto_ptr<int> p;
p.reset (new int);
*p=5;
std::cout << *p << '\n';
p.reset (new int);
*p=10;
std::cout << *p << '\n';
return 0;
}Output:
5
10
函数指针
1、定义
函数指针是指向函数的指针变量。
函数指针本身首先是一个指针变量,该指针变量指向一个具体的函数。这正如用指针变量可指向整型变量、字符型、数组一样,这里是指向函数。
C在编译时,每一个函数都有一个入口地址,该入口地址就是函数指针所指向的地址。有了指向函数的指针变量后,可用该指针变量调用函数,就如同用指针变量可引用其他类型变量一样,在这些概念上是大体一致的。
2、用途:
调用函数和做函数的参数,比如回调函数。
3、示例:
char * fun(char * p) {…} // 函数fun
char * (*pf)(char * p); // 函数指针pf
pf = fun; // 函数指针pf指向函数fun
pf(p); // 通过函数指针pf调用函数fun内存区域划分
一个C/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack): 由编译器自动分配释放,存放函数的参数值、局部变量的值等,其操作方式类似于数据结构中的栈
2、堆区(heap):一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收,注意它与数据结构中的堆是两回事,分配方式倒是类似于链表
3、全局区(静态区 static): 全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化静态变量在相邻的另一块区域,程序结束后由系统释放。
4、文字常量区:常量字符串就是存放在该区,程序结束后由系统释放
5、程序代码区:存放函数体的二进制代码
堆和栈
1、申请方式:
栈:遵循先进后出的规则,它的生长方向是向下的,是向着内存地址减小的方向增长,栈是系统提供的功能。特点是高效快速,缺点是有限制,数据不灵活。它是由系统自动分配的
堆:生长方向是向上的,也就是向着内存地址增加的方向,需要程序员自己申请,并指明大小,
2、申请后系统的响应:
栈:只要栈的剩余空间大于所申请的空间,系统将为程序提供内存,否则将报异常提示栈溢出
堆:首先应该操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时会遍历该链表,寻找第一个空间大于所申请空间的堆节点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样代码中的delete语句才能正确的释放本内存空间,另外由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中
C/C++程序的内存分区的认识。可划分为四大内存分区:堆、栈、全局/静态存储区和代码区。 [1] 不同类型的变量存放的区域不同。
堆区:
由编程人员手动申请,手动释放,若不手动释放,程序结束后由系统回收,生命周期是整个程序运行期间。使用malloc或者new进行堆的申请,堆的总大小为机器的虚拟内存的大小。
说明:new操作符本质上是使用了malloc进行内存的申请,new和malloc的区别如下:
(1)malloc是C语言中的函数,而new是C++中的操作符。
(2)malloc申请之后返回的类型是void*,而new返回的指针带有类型。
(3)malloc只负责内存的分配而不会调用类的构造函数,而new不仅会分配内存,而且会自动调用类的构造函数。
栈区:
由系统进行内存的管理。主要存放函数的参数以及局部变量。在函数完成执行,系统自行释放栈区内存,不需要用户管理。整个程序的栈区的大小可以在编译器中由用户自行设定,VS中默认的栈区大小为1M,可通过VS手动更改栈的大小。64bits的Linux默认栈大小为10MB,可通过ulimit -s临时修改。
全局/静态存储区:
全局/静态存储区内的变量在程序编译阶段已经分配好内存空间并初始化。这块内存在程序的整个运行期间都存在,它主要存放静态变量、全局变量和常量。
注意:
(1)这里不区分初始化和未初始化的数据区,是因为静态存储区内的变量若不显示初始化,则编译器会自动以默认的方式进行初始化,即静态存储区内不存在未初始化的变量。
(2)静态存储区内的常量分为常变量和字符串常量,一经初始化,不可修改。静态存储内的常变量是全局变量,与局部常变量不同,区别在于局部常变量存放于栈,实际可间接通过指针或者引用进行修改,而全局常变量存放于静态常量区则不可以间接修改。
(3)字符串常量存储在全局/静态存储区的常量区,字符串常量的名称即为它本身,属于常变量。
(4)数据区的具体划分,有利于我们对于变量类型的理解。不同类型的变量存放的区域不同。后面将以实例代码说明这四种数据区中具体对应的变量。
代码区:
存放程序体的二进制代码。比如我们写的函数,都是在代码区的。以上所有代码,编译成二进制后存放于代码区,文字常量存放于代码区,是不可寻址的。
总结
数据区包括:堆,栈,全局/静态存储区。
全局/静态存储区包括:常量区(静态常量区),全局区(全局变量区)和静态变量区(静态区)。
常量区包括:字符串常量区和常变量区。
代码区:存放程序编译后的二进制代码,不可寻址区。
可以说,C/C++内存分区其实只有两个,即代码区和数据区。
C++异常
C++ 异常处理
异常是程序在执行期间产生的问题。C++ 异常是指在程序运行时发生的特殊情况,比如尝试除以零的操作。
异常提供了一种转移程序控制权的方式。C++ 异常处理涉及到三个关键字:try、catch、throw。
- throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
- catch: 在您想要处理问题的地方,通过异常处理程序捕获异常。catch 关键字用于捕获异常。
- try: try 块中的代码标识将被激活的特定异常。它后面通常跟着一个或多个 catch 块。
如果有一个块抛出一个异常,捕获异常的方法会使用 try 和 catch 关键字。try 块中放置可能抛出异常的代码,try 块中的代码被称为保护代码。使用 try/catch 语句的语法如下所示:
try
{
// 保护代码
}catch( ExceptionName e1 )
{
// catch 块
}catch( ExceptionName e2 )
{
// catch 块
}catch( ExceptionName eN )
{
// catch 块
}如果 try 块在不同的情境下会抛出不同的异常,这个时候可以尝试罗列多个 catch 语句,用于捕获不同类型的异常。
抛出异常
您可以使用 throw 语句在代码块中的任何地方抛出异常。throw 语句的操作数可以是任意的表达式,表达式的结果的类型决定了抛出的异常的类型。
以下是尝试除以零时抛出异常的实例:
#include<iostream>
using namespace std;
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}
int main(){
// std::cout<<"Hello"<<endl;
cout<<division(3,1)<<endl;
cout<<division(3,0)<<endl;
return 0;
}
3
terminate called after throwing an instance of 'char const*'
--------------------------------
Process exited after 2.596 seconds with return value 3
请按任意键继续. . .
捕获异常
catch 块跟在 try 块后面,用于捕获异常。您可以指定想要捕捉的异常类型,这是由 catch 关键字后的括号内的异常声明决定的。
try
{
// 保护代码
}catch( ExceptionName e )
{
// 处理 ExceptionName 异常的代码
}上面的代码会捕获一个类型为 ExceptionName 的异常。如果您想让 catch 块能够处理 try 块抛出的任何类型的异常,则必须在异常声明的括号内使用省略号 …,如下所示:
try
{
// 保护代码
}catch(...)
{
// 能处理任何异常的代码
}下面是一个实例,抛出一个除以零的异常,并在 catch 块中捕获该异常。
#include <iostream>
using namespace std;
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}
int main ()
{
int x = 50;
int y = 0;
double z = 0;
try {
z = division(x, y);
cout << z << endl;
}catch (const char* msg) {
cerr << msg << endl;
}
return 0;
}Division by zero condition!
--------------------------------
Process exited after 0.03572 seconds with return value 0
请按任意键继续. . .
由于我们抛出了一个类型为 const char* 的异常,因此,当捕获该异常时,我们必须在 catch 块中使用 const char*。当上面的代码被编译和执行时,它会产生下列结果:
Division by zero condition!C++ 标准的异常
C++ 提供了一系列标准的异常,定义在
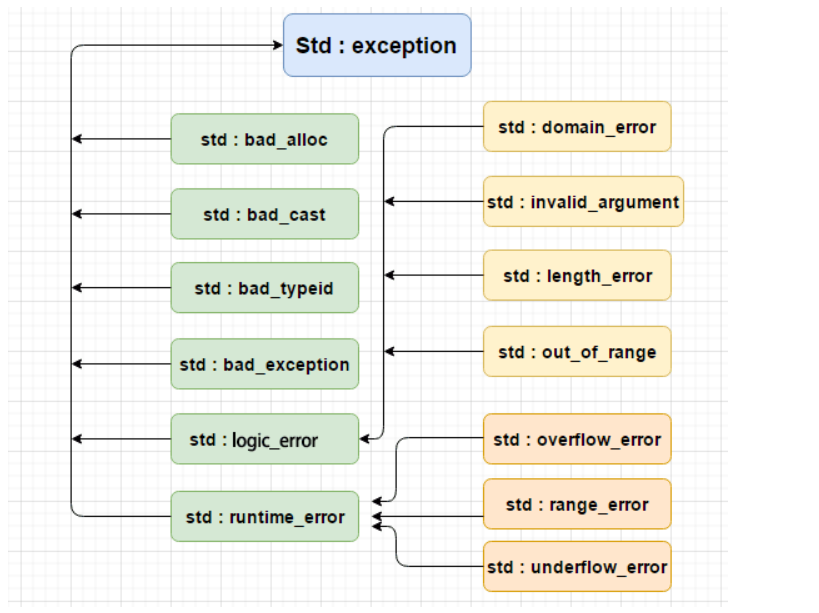
下表是对上面层次结构中出现的每个异常的说明:
定义新的异常
可以通过继承和重载 exception 类来定义新的异常。下面的实例演示了如何使用 std::exception 类来实现自己的异常:
#include <iostream>
#include <exception>
using namespace std;
struct MyException : public exception
{
const char * what () const throw ()
{
return "C++ Exception";
}
};
int main()
{
try
{
throw MyException();
}
catch(MyException& e)
{
std::cout << "MyException caught" << std::endl;
std::cout << e.what() << std::endl;
}
catch(std::exception& e)
{
//其他的错误
}
}MyException caught
C++ Exception
--------------------------------
Process exited after 0.02122 seconds with return value 0
请按任意键继续. . .
在这里,what() 是异常类提供的一个公共方法,它已被所有子异常类重载。这将返回异常产生的原因。
专家指出,长期作息不规律 + 用脑过度的危害很大,可能会诱发神经衰弱、失眠等疾病。我就是受害者之一,曾被失眠困扰了好几年,不但入睡困难,还容易早醒。程序员要注意劳逸结合,多去健身房,多跑步,多打球,多陪女朋友旅游等,千万不要熬夜,以为深夜写代码效率高,这样会透支年轻的身体。
程序的错误大致可以分为三种,分别是语法错误、逻辑错误和运行时错误:
语法错误在编译和链接阶段就能发现,只有 100% 符合语法规则的代码才能生成可执行程序。语法错误是最容易发现、最容易定位、最容易排除的错误,程序员最不需要担心的就是这种错误。
逻辑错误是说我们编写的代码思路有问题,不能够达到最终的目标,这种错误可以通过调试来解决。
运行时错误是指程序在运行期间发生的错误,例如除数为 0、内存分配失败、数组越界、文件不存在等。C++ 异常(Exception)机制就是为解决运行时错误而引入的。
运行时错误如果放任不管,系统就会执行默认的操作,终止程序运行,也就是我们常说的程序崩溃(Crash)。C++ 提供了异常(Exception)机制,让我们能够捕获运行时错误,给程序一次“起死回生”的机会,或者至少告诉用户发生了什么再终止程序。
一个发生运行时错误的程序:
#include <iostream>
#include <string>
using namespace std;
int main(){
string str = "http://google.com";
char ch1 = str[100]; //下标越界,ch1为垃圾值
cout<<ch1<<endl;
char ch2 = str.at(100); //下标越界,抛出异常
cout<<ch2<<endl;
return 0;
}terminate called after throwing an instance of 'std::out_of_range'
what(): basic_string::at: __n (which is 100) >= this->size() (which is 17)
--------------------------------
Process exited after 2.914 seconds with return value 3
请按任意键继续. . .
运行代码,在控制台输出 ch1 的值后程序崩溃。下面我们来分析一下原因。
at() 是 string 类的一个成员函数,它会根据下标来返回字符串的一个字符。与[ ]不同,at() 会检查下标是否越界,如果越界就抛出一个异常;而[ ]不做检查,不管下标是多少都会照常访问。
所谓抛出异常,就是报告一个运行时错误,程序员可以根据错误信息来进一步处理。
上面的代码中,下标 100 显然超出了字符串 str 的长度。由于第 6 行代码不会检查下标越界,虽然有逻辑错误,但是程序能够正常运行。而第 8 行代码则不同,at() 函数检测到下标越界会抛出一个异常,这个异常可以由程序员处理,但是我们在代码中并没有处理,所以系统只能执行默认的操作,即终止程序执行。
捕获异常
可以借助 C++ 异常机制来捕获上面的异常,避免程序崩溃。捕获异常的语法为:
try和catch都是 C++ 中的关键字,后跟语句块,不能省略{ }。try 中包含可能会抛出异常的语句,一旦有异常抛出就会被后面的 catch 捕获。从 try 的意思可以看出,它只是“检测”语句块有没有异常,如果没有发生异常,它就“检测”不到。catch 是“抓住”的意思,用来捕获并处理 try 检测到的异常;如果 try 语句块没有检测到异常(没有异常抛出),那么就不会执行 catch 中的语句。
这就好比,catch 告诉 try:你去检测一下程序有没有错误,有错误的话就告诉我,我来处理,没有的话就不要理我!
catch 关键字后面的exceptionType variable指明了当前 catch 可以处理的异常类型,以及具体的出错信息。演示一下 try-catch 的用法
#include <iostream>
#include <string>
#include <exception>
using namespace std;
int main(){
string str = "http://mosirius.cn";
try{
char ch1 = str[100];
cout<<ch1<<endl;
}catch(exception e){
cout<<"[1]out of bound!"<<endl;
}
try{
char ch2 = str.at(100);
cout<<ch2<<endl;
cout<<"do not do"<<endl;
}catch(exception &e){ //exception类位于<exception>头文件中
cout<<"[2]out of bound!"<<endl;
}
cout<<"have catch [2]"<<endl;
return 0;
}[2]out of bound!
have catch [2]
--------------------------------
Process exited after 0.02306 seconds with return value 0
请按任意键继续. . .
可以看出,第一个 try 没有捕获到异常,输出了一个没有意义的字符(垃圾值)。因为[ ]不会检查下标越界,不会抛出异常,所以即使有错误,try 也检测不到。换句话说,发生异常时必须将异常明确地抛出,try 才能检测到;如果不抛出来,即使有异常 try 也检测不到。所谓抛出异常,就是明确地告诉程序发生了什么错误。
第二个 try 检测到了异常,并交给 catch 处理,执行 catch 中的语句。需要说明的是,异常一旦抛出,会立刻被 try 检测到,并且不会再执行异常点(异常发生位置)后面的语句。本例中抛出异常的位置是第 17 行的 at() 函数,它后面的 cout 语句就不会再被执行,所以看不到它的输出。
检测到异常后程序的执行流会发生跳转,从异常点跳转到 catch 所在的位置,位于异常点之后的、并且在当前 try 块内的语句就都不会再执行了;即使 catch 语句成功地处理了错误,程序的执行流也不会再回退到异常点,所以这些语句永远都没有执行的机会了。本例中,
cout<<"do not do"<<endl; 就是被跳过的代码。
为了演示「不明确地抛出异常就检测不到异常」,将第 10 行代码改为char ch1 = str[100000000];,访问第 100 个字符可能不会发生异常,但是访问第 1 亿个字符肯定会发生异常了,这个异常就是内存访问错误。运行更改后的程序,会发现第 10 行代码产生了异常,导致程序崩溃了,这说明 try-catch 并没有捕获到这个异常。
#include <iostream>
#include <string>
#include <exception>
using namespace std;
int main(){
string str = "http://mosirius.cn";
try{
char ch1 = str[100000000];
cout<<ch1<<endl;
}catch(exception e){
cout<<"[1]out of bound!"<<endl;
}
try{
char ch2 = str.at(100);
cout<<ch2<<endl;
cout<<"do not do"<<endl;
}catch(exception &e){ //exception类位于<exception>头文件中
cout<<"[2]out of bound!"<<endl;
}
cout<<"have catch [2]"<<endl;
return 0;
}--------------------------------
Process exited after 2.185 seconds with return value 3221225477
请按任意键继续. . .
异常的处理流程
抛出(Throw)–> 检测(Try) –> 捕获(Catch)
发生异常的位置
异常可以发生在当前的 try 块中,也可以发生在 try 块所调用的某个函数中,或者是所调用的函数又调用了另外的一个函数,这个另外的函数中发生了异常。这些异常,都可以被 try 检测到。
1.try 块中直接发生的异常:
#include <iostream>
#include <string>
#include <exception>
using namespace std;
int main(){
try{
throw "Unknown Exception of Direct"; //抛出异常
cout<<"This statement will not be executed."<<endl;
}catch(const char* &e){
cout<<e<<endl;
}
return 0;
}Unknown Exception of Direct
--------------------------------
Process exited after 0.02255 seconds with return value 0
请按任意键继续. . .
throw关键字用来抛出一个异常,这个异常会被 try 检测到,进而被 catch 捕获。在 try 块中直接抛出的异常会被 try 检测到。
2.try 块中调用的某个函数中发生了异常:
#include <iostream>
#include <string>
#include <exception>
using namespace std;
void func(){
throw "Unknown Exception of func() "; //抛出异常
cout<<"[1]This statement will not be executed."<<endl;
}
int main(){
try{
func();
cout<<"[2]This statement will not be executed."<<endl;
}catch(const char* &e){
cout<<e<<endl;
}
return 0;
}Unknown Exception of func()
--------------------------------
Process exited after 0.02385 seconds with return value 0
请按任意键继续. . .
func() 在 try 块中被调用,它抛出的异常会被 try 检测到,进而被 catch 捕获。从运行结果可以看出,func() 中的 cout 和 try 中的 cout 都没有被执行。
3.try 块中调用了某个函数,该函数又调用了另外的一个函数,这个另外的函数抛出了异常:
#include <iostream>
#include <string>
#include <exception>
using namespace std;
void func_inner(){
throw "Unknown Exception func_outer(){func_inner();}"; //抛出异常
cout<<"[1]This statement will not be executed."<<endl;
}
void func_outer(){
func_inner();
cout<<"[2]This statement will not be executed."<<endl;
}
int main(){
try{
func_outer();
cout<<"[3]This statement will not be executed."<<endl;
}catch(const char* &e){
cout<<e<<endl;
}
return 0;
}Unknown Exception func_outer(){func_inner();}
--------------------------------
Process exited after 0.3171 seconds with return value 0
请按任意键继续. . .
发生异常后,程序的执行流会沿着函数的调用链往前回退,直到遇见 try 才停止。在这个回退过程中,调用链中剩下的代码(所有函数中未被执行的代码)都会被跳过,没有执行的机会了。
try{
// 可能抛出异常的语句
}catch(exceptionType variable){
// 处理异常的语句
}exceptionType是异常类型,它指明了当前的 catch 可以处理什么类型的异常;variable是一个变量,用来接收异常信息。当程序抛出异常时,会创建一份数据,这份数据包含了错误信息,程序员可以根据这些信息来判断到底出了什么问题,接下来怎么处理。
异常既然是一份数据,那么就应该有数据类型。C++规定,异常类型可以是 int、char、float、bool 等基本类型,也可以是指针、数组、字符串、结构体、类等聚合类型。C++ 语言本身以及标准库中的函数抛出的异常,都是 exception 类或其子类的异常。也就是说,抛出异常时,会创建一个 exception 类或其子类的对象。
exceptionType variable和函数的形参非常类似,当异常发生后,会将异常数据传递给 variable 这个变量,这和函数传参的过程类似。当然,只有跟 exceptionType 类型匹配的异常数据才会被传递给 variable,否则 catch 不会接收这份异常数据,也不会执行 catch 块中的语句。换句话说,catch 不会处理当前的异常。
可以将 catch 看做一个没有返回值的函数,当异常发生后 catch 会被调用,并且会接收实参(异常数据)。
但是 catch 和真正的函数调用又有区别:
- 真正的函数调用,形参和实参的类型必须要匹配,或者可以自动转换,否则在编译阶段就报错了。
- 而对于 catch,异常是在运行阶段产生的,它可以是任何类型,没法提前预测,所以不能在编译阶段判断类型是否正确,只能等到程序运行后,真的抛出异常了,再将异常类型和 catch 能处理的类型进行匹配,匹配成功的话就“调用”当前的 catch,否则就忽略当前的 catch。
总起来说,catch 和真正的函数调用相比,多了一个「在运行阶段将实参和形参匹配」的过程。
另外需要注意的是,如果不希望 catch 处理异常数据,也可以将 variable 省略掉,也即写作:
try{
// 可能抛出异常的语句
}catch(exceptionType){
// 处理异常的语句
}这样只会将异常类型和 catch 所能处理的类型进行匹配,不会传递异常数据了
多级 catch
一个 try 对应一个 catch,这只是最简单的形式。其实,一个 try 后面可以跟多个 catch:
try{
//可能抛出异常的语句
}catch (exception_type_1 e){
//处理异常的语句
}catch (exception_type_2 e){
//处理异常的语句
}
//其他的catch
catch (exception_type_n e){
//处理异常的语句
}当异常发生时,程序会按照从上到下的顺序,将异常类型和 catch 所能接收的类型逐个匹配。一旦找到类型匹配的 catch 就停止检索,并将异常交给当前的 catch 处理(其他的 catch 不会被执行)。如果最终也没有找到匹配的 catch,就只能交给系统处理,终止程序的运行。
多级 catch 的使用:
#include <iostream>
#include <string>
using namespace std;
class Base{ };
class Derived: public Base{ };
int main(){
try{
throw Derived(); //抛出自己的异常类型,实际上是创建一个Derived类型的匿名对象
cout<<"This statement will not be executed."<<endl;
}catch(int){
cout<<"Exception type: int"<<endl;
}catch(char *){
cout<<"Exception type: cahr *"<<endl;
}catch(Base){ //匹配成功(向上转型)
cout<<"Exception type: Base"<<endl;
}catch(Derived){
cout<<"Exception type: Derived"<<endl;
}
return 0;
}Exception type: Base
--------------------------------
Process exited after 0.3305 seconds with return value 0
请按任意键继续. . .
E:\A\coding\Exception.cpp In function 'int main()':
16 6 E:\A\coding\Exception.cpp [Warning] exception of type 'Derived' will be caught
14 6 E:\A\coding\Exception.cpp [Warning] by earlier handler for 'Base'定义了一个基类 Base,又从 Base 派生类出了 Derived。抛出异常时,我们创建了一个 Derived 类的匿名对象,也就是说,异常的类型是 Derived。
我们期望的是,异常被catch(Derived)捕获,但是从输出结果可以看出,异常提前被catch(Base)捕获了,这说明 catch 在匹配异常类型时发生了向上转型(Upcasting)。
C/C++ 中存在多种多样的类型转换,以普通函数(非模板函数)为例,发生函数调用时,如果实参和形参的类型不是严格匹配,那么会将实参的类型进行适当的转换,以适应形参的类型,这些转换包括:
算数转换:例如 int 转换为 float,char 转换为 int,double 转换为 int 等。
向上转型:也就是派生类向基类的转换。
const 转换:也即将非 const 类型转换为 const 类型,例如将 char * 转换为 const char *。
数组或函数指针转换:如果函数形参不是引用类型,那么数组名会转换为数组指针,函数名也会转换为函数指针。
用户自定的类型转换。
catch 在匹配异常类型的过程中,也会进行类型转换,但是这种转换受到了更多的限制,仅能进行「向上转型」、「const 转换」和「数组或函数指针转换」,其他的都不能应用于 catch。
const 转换以及数组和指针的转换:
#include <iostream>
using namespace std;
int main(){
int nums[] = {1, 2, 3};
try{
throw nums;
cout<<"This statement will not be executed."<<endl;
}catch(const int *){
cout<<"Exception type: const int *"<<endl;
}
return 0;
}Exception type: const int *
--------------------------------
Process exited after 0.02301 seconds with return value 0
请按任意键继续. . .
nums 本来的类型是int [3],但是 catch 中没有严格匹配的类型,所以先转换为int *,再转换为const int *。
抛出(Throw)–> 检测(Try) –> 捕获(Catch)
异常必须显式地抛出,才能被检测和捕获到;如果没有显式的抛出,即使有异常也检测不到。
在 C++ 中,我们使用 throw 关键字来显式地抛出异常,它的用法为:
throw exceptionData;
exceptionData 是“异常数据”的意思,它可以包含任意的信息,完全有程序员决定。exceptionData 可以是 int、float、bool 等基本类型,也可以是指针、数组、字符串、结构体、类等聚合类型
char str[] = "http://google.com";
char *pstr = str;
class Base{};
Base obj;
throw 100; //int 类型
throw str; //数组类型
throw pstr; //指针类型
throw obj; //对象类型一个动态数组的例子
C/C++ 规定,数组一旦定义后,它的长度就不能改变了;换句话说,数组容量不能动态地增大或者减小。这样的数组称为静态数组(Static array)。静态数组有时候会给编码代码不便,我们可以通过自定义的 Array 类来实现动态数组(Dynamic array)。所谓动态数组,是指数组容量能够在使用的过程中随时增大或减小。
#include <iostream>
#include <cstdlib>
using namespace std;
//自定义的异常类型
class OutOfRange{
public:
OutOfRange(): m_flag(1){ };
OutOfRange(int len, int index): m_len(len), m_index(index), m_flag(2){ }
public:
void what() const; //获取具体的错误信息
private:
int m_flag; //不同的flag表示不同的错误
int m_len; //当前数组的长度
int m_index; //当前使用的数组下标
};
void OutOfRange::what() const {
if(m_flag == 1){
cout<<"Error: empty array, no elements to pop."<<endl;
}else if(m_flag == 2){
cout<<"Error: out of range( array length "<<m_len<<", access index "<<m_index<<" )"<<endl;
}else{
cout<<"Unknown exception."<<endl;
}
}
//实现动态数组
class Array{
public:
Array();
~Array(){ free(m_p); };
public:
int operator[](int i) const; //获取数组元素
int push(int ele); //在末尾插入数组元素
int pop(); //在末尾删除数组元素
int length() const{ return m_len; }; //获取数组长度
private:
int m_len; //数组长度
int m_capacity; //当前的内存能容纳多少个元素
int *m_p; //内存指针
private:
static const int m_stepSize = 50; //每次扩容的步长
};
Array::Array(){
m_p = (int*)malloc( sizeof(int) * m_stepSize );
m_capacity = m_stepSize;
m_len = 0;
}
int Array::operator[](int index) const {
if( index<0 || index>=m_len ){ //判断是否越界
throw OutOfRange(m_len, index); //抛出异常(创建一个匿名对象)
}
return *(m_p + index);
}
int Array::push(int ele){
if(m_len >= m_capacity){ //如果容量不足就扩容
m_capacity += m_stepSize;
m_p = (int*)realloc( m_p, sizeof(int) * m_capacity ); //扩容
}
*(m_p + m_len) = ele;
m_len++;
return m_len-1;
}
int Array::pop(){
if(m_len == 0){
throw OutOfRange(); //抛出异常(创建一个匿名对象)
}
m_len--;
return *(m_p + m_len);
}
//打印数组元素
void printArray(Array &arr){
int len = arr.length();
//判断数组是否为空
if(len == 0){
cout<<"Empty array! No elements to print."<<endl;
return;
}
for(int i=0; i<len; i++){
if(i == len-1){
cout<<arr[i]<<endl;
}else{
cout<<arr[i]<<", ";
}
}
}
int main(){
Array nums;
//向数组中添加十个元素
for(int i=0; i<10; i++){
nums.push(i);
}
printArray(nums);
//尝试访问第20个元素
try{
cout<<nums[20]<<endl;
}catch(OutOfRange &e){
e.what();
}
//尝试弹出20个元素
try{
for(int i=0; i<20; i++){
nums.pop();
}
}catch(OutOfRange &e){
e.what();
}
printArray(nums);
return 0;
}0, 1, 2, 3, 4, 5, 6, 7, 8, 9
Error: out of range( array length 10, access index 20 )
Error: empty array, no elements to pop.
Empty array! No elements to print.
--------------------------------
Process exited after 0.03362 seconds with return value 0
请按任意键继续. . .
Array 类实现了动态数组,它的主要思路是:在创建对象时预先分配出一定长度的内存(通过 malloc() 分配),内存不够用时就再扩展内存(通过 realloc() 重新分配)。Array 数组只能在尾部一个一个地插入(通过 push() 插入)或删除(通过 pop() 删除)元素。
通过重载过的[ ]运算符来访问数组元素,如果下标过小或过大,就会抛出异常(第53行代码);在抛出异常的同时,我们还记录了当前数组的长度和要访问的下标。
在使用 pop() 删除数组元素时,如果当前数组为空,也会抛出错误。
C++语言本身或者标准库抛出的异常都是 exception 的子类,称为标准异常(Standard Exception)。你可以通过下面的语句来捕获所有的标准异常:
try{
//可能抛出异常的语句
}catch(exception &e){
//处理异常的语句
}之所以使用引用,是为了提高效率。如果不使用引用,就要经历一次对象拷贝(要调用拷贝构造函数)的过程。
exception 类位于
class exception{
public:
exception () throw(); //构造函数
exception (const exception&) throw(); //拷贝构造函数
exception& operator= (const exception&) throw(); //运算符重载
virtual ~exception() throw(); //虚析构函数
virtual const char* what() const throw(); //虚函数
}这里需要说明的是 what() 函数。what() 函数返回一个能识别异常的字符串,正如它的名字“what”一样,可以粗略地告诉你这是什么异常。不过C++标准并没有规定这个字符串的格式,各个编译器的实现也不同,所以 what() 的返回值仅供参考。
下图展示了 exception 类的继承层次:
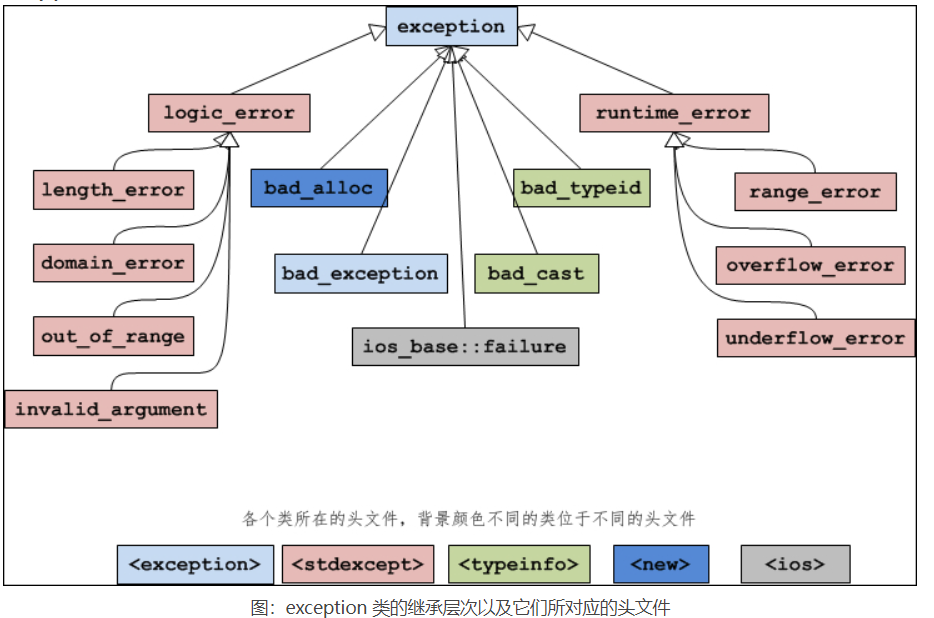
exception 类的直接派生类:
| 异常名称 | 说 明 |
|---|---|
| logic_error | 逻辑错误。 |
| runtime_error | 运行时错误。 |
| bad_alloc | 使用 new 或 new[ ] 分配内存失败时抛出的异常。 |
| bad_typeid | 使用 typeid 操作一个 NULL [指针],而且该指针是带有虚函数的类,这时抛出 bad_typeid 异常。 |
| bad_cast | 使用 dynamic_cast 转换失败时抛出的异常。 |
| ios_base::failure | io 过程中出现的异常。 |
| bad_exception | 这是个特殊的异常,如果函数的异常列表里声明了 bad_exception 异常,当函数内部抛出了异常列表中没有的异常时,如果调用的 unexpected() 函数中抛出了异常,不论什么类型,都会被替换为 bad_exception 类型。 |
logic_error 的派生类:
| 异常名称 | 说 明 |
|---|---|
| length_error | 试图生成一个超出该类型最大长度的对象时抛出该异常,例如 vector 的 resize 操作。 |
| domain_error | 参数的值域错误,主要用在数学函数中,例如使用一个负值调用只能操作非负数的函数。 |
| out_of_range | 超出有效范围。 |
| invalid_argument | 参数不合适。在标准库中,当利用string对象构造 bitset 时,而 string 中的字符不是 0 或1 的时候,抛出该异常。 |
runtime_error 的派生类:
| 异常名称 | 说 明 |
|---|---|
| range_error | 计算结果超出了有意义的值域范围。 |
| overflow_error | 算术计算上溢。 |
| underflow_error | 算术计算下溢。 |